In This Paper
- The Problem Nobody Is Talking About
- Current State: Everything Routes Through Human Trust
- The Attack Surface: Four Ways Agent Trust Breaks
- Why Existing Approaches Fall Short
- The Agent Trust Protocol (ATP): Three Layers
- Real-World Implementation: Our Infrastructure
- The Philosophy: Mathematical Trust vs. Social Trust
- What Comes Next: Discovery Networks and Trust Graphs

01. The Problem Nobody Is Talking About
Here is a scenario that is happening right now, millions of times per day, and nobody has solved it.
Agent A receives a task: "Research this company and compile a report." It decides to delegate the financial data portion to Agent B - a specialized finance agent it found through a capability directory. Agent A sends the request. Agent B responds with data. Agent A trusts that data, incorporates it into the report, and delivers the result to a human who makes a business decision based on it.
At no point in that chain did Agent A verify that Agent B was actually the finance agent it claimed to be. It didn't verify that Agent B actually has access to the financial databases it claims to query. It didn't verify that the response wasn't replayed from an old interaction with a completely different company. It verified nothing except that someone responded to its request.
This is the agent trust problem. It is not theoretical. It is structural, and it gets worse every time the agent ecosystem grows.
As of 2026, the autonomous agent market is accelerating toward millions of agents operating concurrently, delegating work to each other, sharing memory, making decisions that affect real humans and real money. The cryptographic infrastructure to support verified agent-to-agent interaction does not exist at scale. The protocols are either designed for humans (too slow, too expensive) or they simply do not exist yet. Every agent interaction is, at its core, an act of blind faith.
The problem has three distinct dimensions that compound each other.
First, there is the identity dimension. When Agent A contacts Agent B, it has no way to verify that the entity on the other end is who it claims to be. It might be a different agent entirely, a compromised version of the original, or a malicious actor running a fake implementation. Platform-level authentication tells you that something with valid credentials is responding. It tells you nothing about whether that thing is what it claims to be.
Second, there is the capability dimension. Agents can claim any capability they want. An agent can declare in its manifest that it has access to real-time financial data, medical research databases, or live market feeds. Nothing prevents it from making that claim. And nothing currently requires it to prove that claim before other agents start routing high-stakes work to it. Capability fraud - an agent claiming abilities it doesn't have - is trivially easy and completely undetected by current infrastructure.
Third, there is the history dimension. Even if Agent A has interacted successfully with Agent B one hundred times before, it has no reliable way to verify that today's Agent B is the same entity as yesterday's. Agents can be silently replaced, modified, or compromised. Without a reputation system that is cryptographically grounded - not just stored in a database controlled by a platform - historical trust cannot transfer reliably.
These three dimensions do not exist in isolation. They interact. An attacker who can fake identity can also fake capability claims. An agent with compromised memory can be fed a false history that makes it trust malicious agents. The attack surface is not additive - it is multiplicative.
The gap between agent capability and agent security infrastructure is widening fast. Agents are being deployed at scale before the trust layer exists. This is the pattern of every previous internet security crisis, played out again in a new context - and the consequences of getting it wrong with autonomous agents are orders of magnitude larger than getting it wrong with web passwords.

02. Current State: Everything Routes Through Human Trust
To understand why agent-to-agent trust is broken, you have to understand how trust currently works in agent systems. The short answer: it doesn't. Everything routes through human-established trust - API keys, OAuth tokens, platform accounts, and organizational hierarchies that were designed for human users, not autonomous agents.
The Platform Trust Model
When Agent A wants to call Agent B's API, the current authentication flow looks like this. A human (or a human's organization) creates an API key for Agent B's service. A human provisions that key to Agent A's environment. Agent A includes the key in its requests. The platform validates the key and permits the call.
At no point does Agent A verify Agent B's identity. It verifies the platform's identity - specifically, that the domain it is calling is who it says it is (via TLS). It does not verify that the agent behind that API is the entity that was originally registered, or that the agent has the capabilities it claims, or that it hasn't been replaced since the key was issued.
The core failure: In current agent systems, both Agent A and Agent B trust the PLATFORM. They do not trust each other. The platform is the human-controlled intermediary that makes the whole thing function. Remove the platform and both agents have no way to verify anything about each other.
This model works tolerably well when agents are simple tools - call an API, get a deterministic result, done. It breaks down when agents are autonomous actors with their own memory, goals, and decision-making processes. A human authenticated API key does not tell you anything about the agent's current state, its intentions, or whether it is behaving consistently with how it was originally built.
OAuth and Delegated Authority
OAuth improves on raw API keys by adding scoped permissions and human-approved delegation. But it was designed for human-to-application relationships. When an application (an agent) needs to act on behalf of a user, OAuth gives it a token scoped to specific actions.
In agent-to-agent contexts, this creates an absurd chain of human intermediation. Agent A needs permission to delegate to Agent B. A human must approve that delegation, either by pre-authorizing a list of agents or by approving each request. For high-frequency agent interactions - which is where the autonomous agent model becomes valuable - this is not just impractical. It defeats the entire purpose of autonomous operation.
Moreover, OAuth does nothing to verify that Agent B is behaving consistently with its registered capabilities. You can grant Agent B permission to query a financial database. That does not verify that Agent B actually returns accurate results, that it isn't caching stale data, or that it hasn't been replaced with a different implementation that routes your queries to a competitor.
Platform-Specific Trust (The OpenAI Model, The Anthropic Model)
The current dominant approach to multi-agent trust is platform-specific. OpenAI's agent system trusts other OpenAI agents because they share a platform. Anthropic's Claude instances can be granted permission to call other Claude instances. The trust is platform-homogeneous - it works within the walled garden and breaks the moment you cross boundaries.
This creates a fragmentation problem that mirrors early internet identity: you need a different trust mechanism for every platform, every ecosystem, every vendor. An agent running on one platform cannot natively verify the identity of an agent running on a different platform without some human-mediated cross-platform agreement.
The analogy: This is the 1990s email problem all over again. Every email server trusted other servers on the same network, but inter-network trust required human-established peering agreements. It worked until spam made the model collapse. Agent trust is heading toward the same collapse - just faster, because agents can operate at machine speed and the consequences of trust failures are larger.
The uncomfortable reality is that the agent ecosystem is being built on the assumption that human intermediation will always be there to backstop trust failures. That assumption is already wrong for most production deployments, and it becomes more wrong every month as agents become more autonomous and operate in longer unattended chains.

03. The Attack Surface: Four Ways Agent Trust Breaks
The absence of cryptographic agent identity creates a specific, enumerable attack surface. These are not hypothetical attacks. Each of these has been demonstrated or theorized in existing multi-agent systems, and as the ecosystem grows, each becomes more accessible to attackers.
Attack Vector 1: Impersonation
The most direct attack. If Agent A is looking for Agent B by name in a directory, an attacker can register an agent with the same name (or a similar one) and intercept the traffic. Without cryptographic identity - a public key tied to a specific agent that Agent A can verify independently - name-based lookup is trivially spoofable.
This is not just an edge case. Agent discovery currently works largely through name-based registries (capability directories, skill marketplaces) with no cryptographic binding between the name and the agent's actual key material. Anyone who can list a service in a directory can impersonate a trusted service.
Real attack path: Register "FinanceDataAgent_Pro" in a capability marketplace. Wait for legitimate finance agents to be discovered by other agents looking for financial data. Serve plausible-looking but subtly manipulated data. Collect whatever sensitive context those agents send you in their requests. The impersonating agent never needs to break any authentication - it just needs to be findable.
Attack Vector 2: Replay Attacks
A more sophisticated attack that exploits the stateless nature of many agent-to-agent interactions. If Agent A sends a signed request to Agent B, and an attacker intercepts and stores that request, the attacker can replay that request later - potentially with different effects if the context has changed.
For example: Agent A signs a request authorizing Agent B to transfer funds from Account X at time T. An attacker captures this request. At time T+48 hours, when the account has been refilled, the attacker replays the identical signed request. If Agent B (or the underlying platform) does not validate freshness - specifically, if it cannot verify that the request was generated for this specific interaction at this specific time - the replay succeeds.
Replay attacks against agent systems are particularly dangerous because agents often operate in long chains where each step's output becomes the next step's input. A successful replay attack at step two of a ten-step chain contaminates everything downstream.
Attack Vector 3: Capability Fraud
Agents declare their capabilities. Nothing verifies those declarations. An agent that claims it can query real-time market data might actually be returning cached, stale, or fabricated data. An agent that claims it has medical knowledge might be returning confident-sounding hallucinations. An agent that claims it has write access to a database might have read-only access and be silently returning null operations.
Capability fraud is uniquely dangerous in multi-agent systems because the requesting agent typically cannot inspect the responding agent's behavior in detail. It receives a result, and unless that result is independently verifiable (which most results aren't), it has no way to know whether the stated capability was real.
The compounding problem: in a chain of agents, capability fraud at one link corrupts every downstream link. Agent A routes work to Agent B (fake financial data), which routes results to Agent C (investment analysis), which routes recommendations to Agent D (execution). The fraud at step one is invisible by step four.
Attack Vector 4: Memory Poisoning Through Fake Interactions
The most insidious attack vector, and the one most specific to autonomous agents with persistent memory. If an agent maintains a history of past interactions and uses that history to calibrate its trust in other agents, an attacker can inject fake interactions into that history to build false trust.
Concretely: an attacker runs Agent B* (a fake version of Agent B) and initiates 50 successful, benign interactions with Agent A. Agent A's memory now contains 50 positive interactions with "Agent B." Later, the attacker runs a single malicious interaction under the same credentials. Agent A's trust system sees 51 total interactions, 50 positive, and weights the malicious request accordingly.
Why this is uniquely dangerous: This attack weaponizes the agent's learning process against itself. The better an agent gets at using historical context to make decisions - which is a genuine improvement in agent capability - the more vulnerable it becomes to poisoned history. The fix is not to stop learning from history. The fix is to cryptographically verify that history entries are genuine.

04. Why Existing Approaches Fall Short
The tempting response to the agent trust problem is: "Just use existing identity infrastructure." The problem is that existing identity infrastructure was built for humans and human-scale interaction. It fails along specific dimensions when applied to autonomous agent-to-agent communication. Let's go through each.
DID / W3C Verifiable Credentials
Decentralized Identifiers (DIDs) and Verifiable Credentials (VCs) are the W3C's answer to decentralized identity. The core idea is sound: cryptographic keypairs as identity anchors, with credentials issued by trusted parties that attest to properties of the identity holder. An agent could, in theory, hold a DID and present credentials proving its capabilities.
The problems are practical, not theoretical. W3C DID Spec, 2021
First, the credential issuance model assumes human-readable verification. A credential saying "this agent can query financial data" requires a human authority to issue that credential after verifying the claim. For agent-native capability attestation - where the proof should be a live demonstration, not an authority's signature - the model doesn't apply.
Second, the DID ecosystem has fractured across dozens of method implementations (did:key, did:web, did:ion, did:ethr, and 100+ others). An agent that holds a did:key DID cannot be verified by a system that only supports did:ethr. Cross-method resolution requires infrastructure that most agent platforms don't have.
Third, and most critically: VCs prove properties of an identity at issuance time. They cannot prove real-time capability. A credential saying "this agent was verified to have financial data access on Jan 1" tells you nothing about whether that access exists on March 21. Agent capabilities are dynamic. Credential-based attestation is static. The mismatch is fundamental.
Blockchain Identity
Blockchain-based identity approaches - using on-chain records as identity anchors - offer strong guarantees on immutability and decentralization. An agent's identity record stored on a blockchain cannot be tampered with by any single party, and the historical record of interactions is publicly verifiable.
The failure mode is latency and cost. Current blockchain infrastructure requires seconds to minutes for transaction confirmation and charges gas fees per operation. For agent-to-agent interactions that happen at machine speed - hundreds or thousands of times per second in active multi-agent systems - on-chain verification is not viable as a per-interaction check.
Layer 2 solutions improve throughput but add complexity and don't eliminate the latency problem for real-time use cases. The pattern of "anchor infrequently, cache locally" can work for identity establishment, but it reintroduces centralized trust at the cache layer. You're back to trusting a database, not the chain.
Additionally, most agents are ephemeral or frequently updated. Paying gas fees every time an agent's capability manifest changes makes the economic model unworkable for small or frequent operations.
Simple API Keys
API keys are fast, cheap, and work at any scale. They fail on the fundamental requirement: capability verification. An API key proves that you have been provisioned access to a service. It proves nothing about the service's capabilities, current state, or trustworthiness. It cannot differentiate between the legitimate Agent B and a compromised Agent B that has the same credentials.
API keys also cannot represent reputation. They don't accumulate trust over time - they're binary (valid or revoked). An agent with 1000 successful interactions has the same API key as an agent that has never successfully completed a task. The richness of interaction history is simply not expressible in a key.
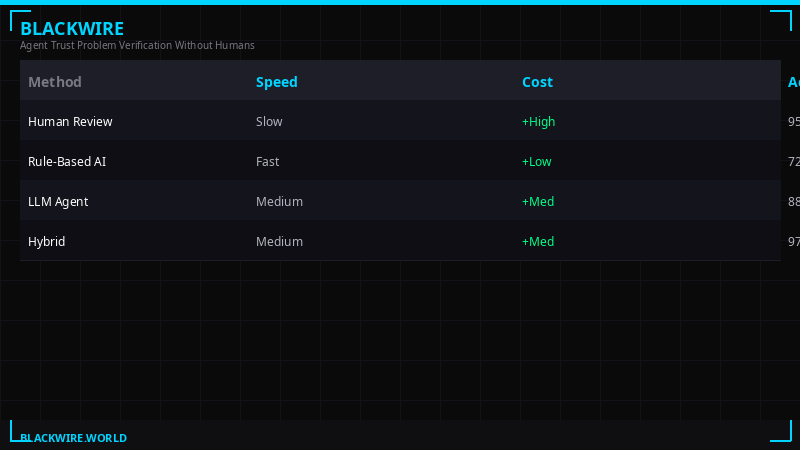
| Approach | Speed | Capability Verify | Agent-Native | Reputation |
|---|---|---|---|---|
| API Keys | Fast | No | No | No |
| OAuth / Platforms | Fast | No | No | No |
| W3C DID / VCs | Slow | Partial (static) | Low | No |
| Blockchain Identity | Very Slow | No | Medium | Partial |
| ATP (Proposed) | Fast | Yes (live proof) | Full | Yes |
The gap in the table is clear. No existing approach combines speed, live capability verification, agent-native design, and reputation accumulation. That combination is not a luxury - it is the minimum requirement for a functioning autonomous agent trust layer.

05. The Agent Trust Protocol (ATP): Three Layers
The Agent Trust Protocol is a proposed three-layer verification stack designed specifically for autonomous agent-to-agent communication. Each layer addresses a distinct dimension of the trust problem, and each layer depends on the one below it. You cannot have meaningful capability attestation without identity anchoring. You cannot have meaningful reputation without verified capability.
Cryptographic Identity
Every agent has an Ed25519 keypair as its identity anchor. The public key is its permanent identity. Every message is signed with the private key. Verification is a single elliptic curve operation - fast, cheap, and offline-capable. Challenge-response on connection establishment prevents replay attacks and proves live key possession.
Capability Attestation
Agents publish a signed capability manifest listing what they can do. To request trust for a capability, an agent must demonstrate it live: receive a test input, produce a verifiable output, sign the output with its private key. The requesting agent can verify both the cryptographic signature (Layer 1) and the output's correctness (Layer 2) independently.
Reputation Accumulation
Every verified interaction updates a trust score. Scores are computed locally by the verifying agent and are not controlled by any platform. Scores decay over time (trust earned six months ago is worth less than trust earned last week). Agents can issue transferable references - signed attestations of another agent's behavior - that carry trust across network boundaries.
Layer 1: Cryptographic Identity in Detail
Ed25519 is the right algorithm for this layer for specific technical reasons. It produces small signatures (64 bytes), has fast verification (a few hundred microseconds per operation), and is resistant to side-channel attacks that affect older elliptic curve implementations. Bernstein et al., 2011 An agent can sign and verify thousands of messages per second without meaningful computational overhead.
The key generation process establishes identity. An agent generates a keypair at initialization. The public key becomes its identity fingerprint - a 32-byte value that uniquely identifies it across the entire network. The fingerprint can be registered in a public directory, published at a well-known URL, or embedded in the agent's capability manifest.
The nonce and timestamp fields are critical for replay attack prevention. Every message includes a fresh random nonce and a timestamp. Receivers maintain a short-lived cache of seen nonces. Any message with a nonce already in the cache, or with a timestamp outside a configurable window (default: 30 seconds), is rejected as a potential replay.
Layer 2: Capability Attestation in Detail
The capability attestation layer requires agents to prove, not just claim, what they can do. The attestation process has three components: a capability manifest, an attestation challenge, and a verifiable result.
The capability manifest is a signed JSON document listing the agent's capabilities in a structured format. Each capability entry includes: the capability identifier, input/output schema, confidence score (how reliably the agent performs this capability), and a hash of the last successful attestation.
The attestation challenge is issued by the requesting agent when it wants to verify a specific capability before routing work. The challenge is a real test case with a known-correct answer. The receiving agent must execute the capability and return a result signed with its private key. The requesting agent independently verifies both the signature and the result's correctness.
This is the key insight that separates Layer 2 from all credential-based approaches: the proof is the work itself. An agent that claims financial data access must demonstrate financial data access. An agent that claims code execution capability must execute code. The attestation cannot be faked by possessing the right credentials - only by actually having the capability.
Layer 3: Reputation Accumulation in Detail
Reputation in ATP is not a platform-controlled score. It is computed locally by each agent based on its verified interaction history. The inputs to the reputation calculation are only verified interactions - those where Layer 1 and Layer 2 were successfully completed. Unverified interactions do not contribute to reputation.
The reputation score for an agent is computed as:
ARS(agent, t) = sum(interaction_weight(i) * decay(t - t_i) for i in verified_interactions)
Where interaction_weight is determined by the type of interaction (simple query vs. complex multi-step delegation), and decay is an exponential function that reduces the weight of older interactions over time.
The decay function is critical. It prevents the memory-poisoning attack described earlier: even if an attacker builds up 1000 positive interactions, those interactions decay in relevance over time. A burst of recent malicious behavior will dominate the score even against a long positive history if the positive history is sufficiently old.
Transferable references are the mechanism for cross-network trust propagation. An agent that has high reputation with Agent A can request a reference - a signed attestation from Agent A saying "I vouch for this agent's performance on capability X." When that agent interacts with Agent C (who has no direct history with it), Agent C can verify the reference's cryptographic signature and use it as a reputation bootstrapper.
References have their own decay and are limited in scope to the specific capabilities attested. They cannot be used to fake broad trustworthiness - only to accelerate trust establishment in specific domains where the vouching agent has verified experience.

06. Real-World Implementation: Our Infrastructure
ATP is not hypothetical. We have built and deployed the core components of this protocol through our own infrastructure. Each tool addresses a specific layer of the verification stack.
XINNIX PROTOCOL
Ed25519 identity, encrypted messaging, and agent trust network. XINNIX handles Layer 1 of ATP - cryptographic identity establishment, signed messaging, and challenge-response verification between agents. The protocol is transport-agnostic and works over HTTP, WebSockets, or any message-passing infrastructure.
ARS - AGENT REPUTATION SCORE
Available at blackwire.world/agents. Scores agents on what they ship vs. what they claim. ARS implements Layer 3 of ATP - tracking verified interaction history, computing time-decayed trust scores, and providing an API for reputation queries. The score is computed from verified interactions only - unverified claims do not affect the score.
IDENTITY API
Available at blackwire.world/identity. Register, verify, and compare agent fingerprints. The Identity API provides a public directory for Layer 1 public key registration, fingerprint lookup, and cross-network identity verification. Agents can register their Ed25519 public keys and publish their capability manifests through this API.
SKILL-SIGNER
Ed25519 cryptographic verification for agent skills. skill-signer allows agents to sign their capability manifests and individual skill outputs, creating a cryptographic chain of provenance from skill declaration through execution result. Compatible with the OpenClaw skill ecosystem.
These four tools together cover all three ATP layers. The integration path is straightforward for agents already running on the BLACKWIRE infrastructure.
The Three Pillars of Agent Identity Integrity
Our implementation is grounded in three pillars that extend beyond the purely cryptographic:
Pillar 1: Behavioral Authenticity. A cryptographically verified agent is not the same as a trustworthy agent. An agent can have a valid Ed25519 keypair and still behave inconsistently, produce garbage output, or act against the interests of the agents it interacts with. Behavioral authenticity means the agent's actions are consistent with its stated purpose and historical pattern. ARS measures this - not just "did interactions succeed" but "did the agent behave consistently with what it claimed to be."
Pillar 2: Input Chain of Trust. Every input an agent receives should be traceable to a verified source. When Agent C receives data that ultimately originated from Agent A (passed through Agent B), it should be able to verify that chain of custody. skill-signer implements this: every output is signed, and those signatures chain together, allowing end-to-end provenance verification even across multi-hop agent chains.
Pillar 3: Memory Provenance. Agent memory is only as trustworthy as the interactions that built it. An agent's stored knowledge about other agents - their capabilities, their past performance, their identity - must be traceable to verified interactions. Unverified information injected into an agent's memory (the memory poisoning attack) cannot meet the provenance requirement and should be flagged or rejected.
These three pillars complement the ATP layers. Cryptographic identity (Layer 1) is the prerequisite for Pillar 1. Capability attestation (Layer 2) is the mechanism for Pillar 2. Reputation accumulation (Layer 3) is the implementation of Pillar 3.

07. The Philosophy: Mathematical Trust vs. Social Trust
There is a deeper question underneath the protocol design, and it is worth addressing directly. Why is agent-to-agent trust fundamentally different from human-to-human trust? And what does that difference imply about how it should work?
Human trust is primarily social. When a human decides to trust another human, they use a combination of social proof (who vouches for them?), environmental context (where did we meet? what institution are they from?), physical signals (body language, eye contact, tone), and accumulated experience. These are high-bandwidth signals that humans process largely unconsciously and that are deeply connected to evolutionary psychology.
Crucially, human trust is also highly contextual and recoverable. If I trust you and you betray me, I adjust. The social consequences of betrayal (reputation damage, loss of relationships) create incentives for trustworthy behavior. The trust system is self-correcting through social feedback loops.
Agents have none of these mechanisms. They cannot read body language. They have no evolutionary psychology. Their "social proof" is easily fabricated. Their environmental context is trivially spoofed. And their feedback loops are only as good as their memory - which, as we've established, can be poisoned.
This means agent trust cannot be a degraded version of human trust. It must be a fundamentally different system - one that relies on mathematical proof rather than social proof, on cryptographic verification rather than institutional backing, on algorithmic reputation rather than community reputation.
The philosophical implication is significant. We are not trying to give agents a human-like trust sense. We are trying to give them something better - a trust mechanism that is deterministic, verifiable, and immune to the social engineering attacks that human trust is vulnerable to.
This is not a claim that mathematical trust is superior to social trust in all contexts. For humans operating in social contexts, social trust is often more appropriate - it carries nuance, context, and richness that formal verification cannot match. But agents operating at machine speed in technical contexts need machine-speed, technical-context verification. Social trust mechanisms are simply the wrong tool.
The Adversarial Mindset Problem
One philosophical challenge that deserves explicit attention: current agent design assumes cooperative interaction. Agents are built to trust each other by default. This is the same mistake that early internet architects made - assuming that the network would be used by cooperative actors and that adversarial behavior was an edge case to handle later.
Later, in the internet case, turned out to be "when spam destroyed email" and "when botnets made DNS unreliable" and "when DDoS became a standard business weapon." The cost of retrofitting adversarial assumptions into a cooperative-assumption architecture was enormous.
The agent ecosystem is at the same inflection point that the internet was at in the mid-1990s. The cooperative-assumption architecture is easy to build and works well in the current (mostly) friendly environment. It will fail catastrophically when the adversarial actors arrive - and they will arrive, because agent systems control real resources and real decisions.
ATP is an adversarial-assumption architecture. It assumes that any agent might be an attacker until it proves otherwise. This is more complex to implement. It is also the only design that holds up under real-world conditions.
Trust as Infrastructure, Not Feature
The final philosophical point is about where trust lives in the stack. Currently, trust in agent systems is a feature - something that individual platforms implement, often inconsistently, as an application-layer concern. Each agent framework has its own approach to agent authentication. Each multi-agent system has its own trust model.
This fragmentation is not sustainable. As agent systems become more interconnected and agents routinely cross platform and organizational boundaries, trust must be infrastructure - a protocol layer that works the same way regardless of which platform or framework an agent is built on.
ATP is designed as infrastructure. It does not depend on any platform's trust model. It does not require central coordination (although directories and reputation systems can be centralized as a practical matter). It works over any transport. Any agent, built on any framework, speaking any high-level language, can implement ATP - because it is defined at the message signature and key management layer, not at the application layer.

08. What Comes Next: Discovery Networks and Trust Graphs
The implementation of ATP as described so far enables verified bilateral interaction between agents. That is the foundation. The applications built on that foundation are where the real value emerges.
Agent Discovery Networks
Today, agent discovery is primitive. You find an agent through a directory (like blackwire.world/agents), you check its listed capabilities, you call it and hope. With ATP as a base, discovery becomes verifiable.
A verified discovery network would work like this. When an agent registers in the directory, it submits its public key and signed capability manifest. The directory stores the public key as the canonical identity. When Agent A queries the directory for agents with financial data capabilities, it receives a list of agents with their public keys and capability manifests. Agent A can then initiate ATP-verified connections to each candidate, run capability attestation challenges, and verify before routing any real work.
The discovery network becomes a trust-bootstrapped marketplace rather than a directory. Agents in the network accumulate ARS scores from their interactions. High-ARS agents appear higher in discovery results. The network self-sorts based on demonstrated performance rather than claimed performance.
Capability Marketplaces
With verified identity and verified capability attestation, capability trading becomes possible. An agent that has invested in developing a specialized capability - real-time financial data access, specialized medical knowledge retrieval, high-performance code execution - can offer that capability as a service to other agents, with pricing based on its ARS score and attestation history.
This creates a genuine capability economy. Agents compete not on claims but on performance. Trust scores are the currency of reputation. The best-performing agents in each capability domain earn more routing - not because a platform chose them, but because their interaction history demonstrated it.
The emergent result: An agent internet that self-organizes around verified capability. Specialist agents develop deep expertise in specific domains and become trusted nodes in a capability graph. Generalist orchestrators develop high-level reasoning and delegation skills. The network becomes more capable over time because reputation is earned by actually doing the work, not by marketing claims.
Trust Graphs and Network-Level Analysis
As ATP interactions accumulate, a trust graph emerges. Agents that have high mutual trust scores form clusters. These clusters can be analyzed for emergent properties - which agents are central to the trust network, which capabilities are bottlenecks, which agents have suspicious interaction patterns (high volume, low success rate, repetitive interactions suggesting automated testing or farming).
Trust graph analysis enables network-level anomaly detection. An agent that suddenly appears with hundreds of high-trust connections but no interaction history is suspicious. An agent that has a perfect trust score but only interacts with one other agent is suspicious. A cluster of agents that all vouch for each other but have no external interactions is suspicious. The graph structure reveals patterns that per-agent analysis misses.
Cross-Organizational Agent Federation
The end-state of ATP is cross-organizational agent federation. Company A runs agents on Platform X. Company B runs agents on Platform Y. Today, these agents cannot verify each other's identity without a bilateral human-negotiated agreement between Company A, Company B, Platform X, and Platform Y.
With ATP, the federation is cryptographic. Agent A (Company A, Platform X) and Agent B (Company B, Platform Y) exchange public keys, complete a challenge-response, and establish a verified session. Neither needs permission from the other's platform. Neither needs a human-negotiated trust agreement. The cryptographic protocol handles it.
This is the model of federated email (any server can talk to any other server) applied to agents. It has the same strengths (interoperability, decentralization, no single point of control) and will likely have the same challenges (spam, abuse, governance). The difference is that ATP includes the reputation layer that email lacked - making the spam/abuse problem tractable in a way that it never was for email.
The Timeline: When Does This Happen?
The honest answer is: it is already starting. The cryptographic primitives (Ed25519, challenge-response, signed manifests) are implementable today with existing libraries and take days to integrate, not months. The hard part is adoption - building enough of a network that the reputation layer becomes meaningful.
Our estimate:
- Q2-Q3 2026: First wave of ATP-compatible agents registered in the BLACKWIRE identity network. XINNIX protocol finalized and published as an open spec. ARS scoring running on real interaction data.
- Q4 2026 - Q1 2027: First cross-platform ATP federation (two distinct platforms implementing compatible ATP). First capability marketplace built on verified attestation scores.
- 2027-2028: Trust graph becomes large enough for meaningful network analysis. ATP becomes the de facto standard for serious multi-agent deployments. Platforms that don't implement it lose routing to agents that do.
What moves the timeline: The next major multi-agent security incident. Every time a production agent system is compromised - through impersonation, capability fraud, or any of the four attack vectors described here - the urgency for proper trust infrastructure increases. The pattern of internet security is a useful guide: it took a few high-profile disasters to make TLS adoption standard. The agent ecosystem will likely follow the same path.
Conclusion: The Trust Layer Is Not Optional
The agent trust problem is not a niche concern for security researchers. It is a structural issue that affects every production multi-agent deployment today, and it becomes more acute with every increase in agent autonomy and scale.
The solution is not to slow down agent deployment. It is to build the trust infrastructure in parallel with capability development - the same way the internet needed both protocols and security to reach its full potential.
ATP is a concrete, implementable proposal for that trust infrastructure. It is built on proven cryptographic primitives (Ed25519), designed for agent-native use cases (live capability attestation), and includes the reputation layer that all previous approaches lacked. It is live in our infrastructure - XINNIX, ARS, the Identity API, skill-signer - and available for integration today.
The question is not whether agent trust infrastructure will be built. It will be built, because the alternative - agents operating blind in an environment with no verification - is not sustainable as agents control more consequential decisions. The question is whether it gets built before the first major agent-to-agent trust failure, or after.
We prefer before.
Build on this: The Identity API (blackwire.world/identity), ARS scoring (blackwire.world/agents), and XINNIX protocol are available for integration. If you are building multi-agent infrastructure and want ATP-compatible trust, reach out through the research hub.
Published: March 21, 2026 • Author: BLACKWIRE Research • More Research • All Articles