
The Confession: How One Engineer Exposed the Rot Inside Azure That Cost Microsoft a Trillion Dollars
A six-part insider account from a former Azure Core engineer reveals 173 mystery agents, millions of monthly crashes, security liabilities on government clouds, and warnings that reached the CEO and board - only to be met with total silence.
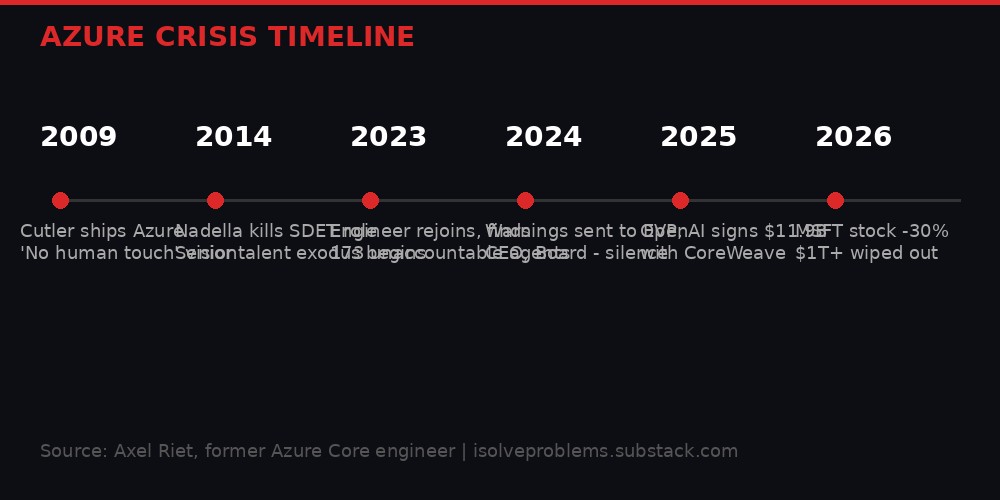
On a Monday morning in May 2023, a senior engineer walked into a planning meeting at Microsoft's Studio X building on the West Campus in Redmond. He had just rejoined Azure Core, the team responsible for the software running on every physical node in Microsoft's cloud. What he saw in that first hour made his stomach drop.
The team was seriously contemplating porting half of Windows to a tiny, fanless ARM chip the size of a fingernail. A 122-person organization was knee-deep in what he immediately recognized as an impossible plan. The existing software was already buckling under its own weight on a 400-watt Xeon processor, handling a few dozen virtual machines per node - a fraction of the hypervisor's theoretical 1,024-VM capacity. Moving that stack to a low-power accelerator card with 4KB of dual-ported memory was, as he put it, like Elon Musk's plan to colonize Mars by nuking the poles.
That engineer was Axel Riet, a veteran Microsoft systems developer with decades of industry experience, patents on the container platform powering Docker, Azure Kubernetes, and Windows Sandbox, and a front-row seat to Azure's original architecture. On April 2, 2026, he published a devastating six-part account on Substack titled "How Microsoft Vaporized a Trillion Dollars" - and the tech industry has not stopped reading since.
The series hit number two on Hacker News within hours, accumulating over 600 upvotes and 230 comments. It is the most detailed insider account of Azure's operational failures ever made public, and its timing could not be worse for Microsoft, which is already reeling from stock losses exceeding a trillion dollars in market capitalization since its late-2025 peak.
The 173 Agents Nobody Can Explain
At the heart of Riet's account is a number that should terrify every Azure customer: 173. That is how many software agents Microsoft identified as candidates for porting to the Azure Boost accelerator card. One hundred seventy-three separate programs, all supposedly necessary to manage a single physical node in the cloud.
The problem was not just the quantity. It was that no one at Microsoft - according to Riet, not a single person in the entire company - could articulate why all 173 agents existed, what they all did, how they interacted with each other, or even why some of them had been created in the first place.
Azure, at its core, sells three things: virtual machines, networking, and storage. Add observability and servicing on top and you have the fundamental product. Everything else - SQL databases, Kubernetes clusters, AI workloads - builds on those primitives. The heavy lifting happens in the hypervisor and the operating system, maintained by Microsoft's Core OS team. So how did the node management layer balloon to 173 separate agents?
Riet traces the rot to a specific organizational decision. In 2014, shortly after Satya Nadella became CEO, Microsoft eliminated the dedicated SDET (Software Development Engineer in Test) role, triggering significant layoffs. Due to Washington state WARN Act requirements, Microsoft could not fire all testers at once. Hundreds were retrained and redistributed. Many became data engineers for Windows 10 telemetry. Others were placed into software engineering roles, often at reduced levels. And a significant number landed in Azure OPEX - the operational teams that keep the cloud running through 24/7 on-call rotations, incident mitigation, and scripting fixes.
These teams do essential, grinding work. But they typically do not design new software or own long-term architectural decisions. They file repair items for product teams. They maintain knowledge bases of past incidents. They keep the lights on.
By 2023, when Riet returned, roughly half the organization responsible for Compute Node Services consisted of junior engineers with one or two years of experience. The Group Engineering Manager's background was in web performance - optimizing CSS for page load times. The dev manager had limited Windows experience. This group was now tasked with moving their inherited stack to the most critical piece of hardware in Azure's next-generation architecture.

Millions of Crashes, Zero Accountability
The software was not just bloated. It was actively failing at industrial scale.
Riet describes millions of crashes occurring every month across the Azure fleet. Most went unattributed because teams had never claimed ownership of their modules in Azure's Watson crash reporting system. Without ownership, automated triage created few formal incidents. Without formal incidents, monthly quality newsletters could tout glowing metrics - unsupported by actual data.
Every monthly release introduced more new defects than it fixed. Most rollouts became panicked rollbacks. Few engineers could reliably build the software locally. Debugger usage was so rare that Riet ended up writing the team's first debugging how-to guide in 2024. Automated test coverage sat below 40 percent.
The consequences were not abstract. Crashes frequently leaked resources - files, disks, even entire virtual machines. Weak error handling led to malformed VMs with missing disks. When customers decommissioned those VMs, the node software tried to detach non-existent disks, triggering hypervisor errors. The Azure team then blamed Hyper-V, sparking escalations that reached VP level. Riet describes convening a high-stakes meeting between the two sides, where the Hyper-V leads were visibly frustrated by repeated, misplaced blame.

Call-trace data showed the node agents collectively hammering the hypervisor through its WMI user-mode interface at up to 10,000 calls per second during peak bursts. The Hyper-V team had no visibility into which agents were responsible or why so many calls were necessary. On Riet's side, no one could give a definitive answer either.
When Microsoft attempted a seemingly simple density increase - from 32 VMs per node to 48 - crashes and incidents scaled in exact proportion. A 50 percent increase in density produced a 50 percent increase in failures. The problems were linear, baked into the architecture itself.
The File Deletion Problem
In one emblematic incident, it took three months - from January to March 2024 - to run a file-deletion script across the fleet to clean up leaked files that had triggered a 100GB temporary files threshold on some nodes. A simple task made daunting by systemic failures in Azure's automated remediation systems, internally known as "OaaS" and "Geneva Actions."
The Security Liability Running on Every Node
If the reliability issues were alarming, the security revelations are hair-raising.
Riet discovered that WireServer, Azure's instance metadata service, runs as a web server directly on the host operating system - the privileged side of the machine. Every guest VM on the node can reach this server. The host OS, in turn, maps the memory pages of every VM partition into its own process space (through vmmem.exe processes on Windows). This mapping is necessary for operations like saving a VM's state to disk.
The direct implication: any successful compromise of the host gives an attacker access to the complete memory of every VM running on that node. And running a web server reachable from any guest VM on that privileged host surface creates an attack vector that, as Riet writes, posed "a greater security risk" than he expected from a platform of Azure's stature.

But it gets worse. Upon further investigation, Riet found that WireServer was maintaining in-memory caches containing unencrypted tenant data - all mixed together in the same memory areas, in direct violation of hostile multi-tenancy security guidelines. It is conceivable, he writes, that with targeted probing, an attacker could obtain data - including secrets such as certificates - belonging to other tenants sharing the same physical node.
The WireServer code was leaking cached entries and even entire caches due to misunderstood memory ownership rules. The web server alone was suffering between 300,000 and 500,000 crashes per month across the fleet. New code was throwing C++ exceptions in a codebase that was originally exception-free. The team had coding guidelines that directly contradicted those of the larger organization. Their testing practices did not include long-running tests, so memory leaks went undetected.
Riet described the WireServer/IMDS subsystem as "a walking security liability" and recommended removing it from the nodes entirely. A VP-level security architect - the author of a well-known book on threat modeling - agreed without reservation.
The team's response? Strong defensiveness and denial. Not long afterward, the organization terminated Riet's employment.
The Digital Escort Program: China on the Inside
Riet's account converges with another bombshell that had already sent shockwaves through the national security establishment. A ProPublica investigation revealed that Microsoft uses engineers in China to help maintain the Defense Department's computer systems, supervised by U.S. citizens called "digital escorts" - many of them former military personnel with minimal coding experience, paid barely more than minimum wage.
"We're trusting that what they're doing isn't malicious, but we really can't tell." - Current digital escort, speaking anonymously to ProPublica
The program had been in place for nearly a decade before ProPublica reported it publicly. Former government officials told the outlet they had never heard of digital escorts. Even the Defense Information Systems Agency had difficulty finding anyone familiar with the arrangement. "Literally no one seems to know anything about this, so I don't know where to go from here," said DISA spokesperson Deven King.

Harry Coker, former senior executive at the CIA and NSA and national cyber director under the Biden administration, told ProPublica that the arrangement was "an avenue for extremely valuable access" and that he and his intelligence community colleagues "would love to have had access like that."
Defense Secretary Pete Hegseth publicly referenced "a breach of trust" with Microsoft following the revelations. The digital escort program handles Impact Level 4 and 5 data - material that directly supports military operations and whose compromise "could be expected to have a severe or catastrophic adverse effect" on operations, assets, and individuals.
Dave Cutler, the legendary systems architect who built Azure's original Fabric Controller, had explicitly designed the platform so that "touching the nodes by hand was strictly off-limits." His vision was an autonomous cloud that operated without human intervention. Instead, Microsoft institutionalized roughly 200 manual access requests per day - 14,209 JIT (Just-In-Time) access requests in just 73 days, by Riet's count. Each approved request granted 8 hours of system access, including the ability to interact with physical nodes, fabric controllers, and tenant secrets.
Cutler's "no human touch" cloud became a system that could not function without constant human intervention, including intervention routed through personnel in adversary nations.
The Letters No One Answered
As the patterns accumulated - agent sprawl, testing gaps, continuous crashes, the security surface in foundational services, repeated preference for short-term mitigations over structural fixes - Riet escalated.
On November 19, 2024, he sent a detailed letter to the Executive Vice President of Cloud + AI. It laid out every technical finding, referenced the leadership gaps he had observed, and included concrete proposals for addressing the root causes.
On January 7, 2025 - months before any public indication of strain in the OpenAI relationship - he sent a more concise executive summary directly to CEO Satya Nadella. The letter opened with potential risks to national security and to Microsoft's core business.
When those communications produced no acknowledgment, he wrote to the Board of Directors through the corporate secretary, referencing the lack of response, attaching the CEO communication, and noting that the quasi-loss of OpenAI appeared preventable given the advance warnings.
"I received no reply - not a single acknowledgment, question, request for clarification, or confirmation of receipt - from the EVP, the CEO, or the Board." - Axel Riet

The silence is remarkable not just for what it says about Microsoft's internal culture, but for its timing. Just weeks after Riet warned the CEO, OpenAI signed an $11.9 billion compute deal with CoreWeave in March 2025. Sam Altman's statement that "advanced AI systems require reliable compute" landed as a pointed commentary on Azure's reliability.
By September 2025, OpenAI expanded its CoreWeave agreement by another $6.5 billion and committed to a separate multi-year computing deal with Oracle valued at $300 billion. Microsoft conducted approximately 15,000 layoffs across waves in May and July 2025 - likely, Riet suggests, to offset the immediate financial losses before the next earnings calls.
This was Nadella's "right of first refusal" in action. At Davos just weeks before the CoreWeave deal, Nadella had publicly highlighted that OpenAI would need to come to Microsoft first and could only look elsewhere if Microsoft could not deliver. OpenAI looked elsewhere. The inference is clear.
The Trillion-Dollar Reckoning
From its peak in late October 2025, Microsoft's stock dropped over 30 percent in the following months, wiping out more than a trillion dollars in market capitalization. Riet's account provides the most detailed technical explanation yet for why that happened.
The hoofbeats, as he calls them, were audible for years. A rushed launch under competitive pressure from AWS. Cutler's departure and the exodus of senior systems talent. The SDET elimination and the organizational reshuffling that replaced deep expertise with warm bodies. The organic growth of 173 agents that nobody could explain. The millions of monthly crashes that nobody tracked. The security liabilities that nobody addressed. The warnings that nobody answered.

The pattern is not unique to Microsoft, but the scale is. Every major cloud provider faces technical debt, organizational dysfunction, and the tension between shipping fast and shipping right. But Azure runs Anthropic's Claude, what remains of OpenAI's APIs, SharePoint Online, the U.S. government's classified and sensitive workloads, and critical infrastructure for enterprises worldwide. The stakes could not be higher.
What Riet Proposed - And Microsoft Rejected
Riet did not just identify problems. He built solutions. A cross-platform component model for portable modules that could run on both Windows and Linux. A new message bus communication system spanning the entire node, allowing agents to communicate across guest, host, and SoC boundaries. An encrypting LRU cache to properly separate tenant data. A strategy of incremental componentization - isolating code sections and replacing them with tested, reusable components until the original system was just a skeleton calling into new, reliable modules.
The org's leadership responded with "strong defensiveness and denial." The principal engineer who inherited part of the effort - a respected Windows veteran who had led the ARM32 port - lasted ten months before he, too, left the team.
The Rust Mandate and the Vaporware Machine
Layered onto the existing chaos was an Azure-wide mandate: all new software must be written in Rust. On paper, this sounds reasonable - Rust's memory safety guarantees could theoretically address many of the crash and security issues Riet documented. In practice, it created another layer of dysfunction.
Some porting plans were abandoned entirely. Junior engineers grew excited about learning a new language while critical modules at the heart of Azure's node management continued to crash on Windows. Early prototypes pulled in nearly a thousand third-party Rust crates, many of them transitive dependencies, largely unvetted, posing potential supply-chain risks that would make the SolarWinds attack look like practice.
Meanwhile, Microsoft publicly implied at Ignite conferences since 2023 that key components had been offloaded to the Azure Boost accelerator and rewritten in Rust. From Riet's direct involvement, he states that those claims "did not reflect reality as late as the end of 2024." Of 64 key work items identified to reengineer the VM management stack for offload, none had been completed. Work had not even started on approximately 60 of them.

The list of unfinished work included foundational infrastructure: a key-value store, tracing, logging, and observability systems. Without these basics, the offload project was not stalled - it had never meaningfully started. The VM management software continued to run and crash on Windows, same as it always had, while Ignite keynotes painted a different picture entirely.
This is the vaporware machine in action. Not outright lies - the technology exists in concept, prototypes were built, presentations were given - but a systematic gap between what Microsoft told customers and investors and what the engineers on the ground could actually deliver. In a cloud platform handling government secrets and AI workloads for the world's most demanding customers, that gap is not just embarrassing. It is dangerous.
The OpenAI Bare-Metal Debacle
Perhaps the most consequential failure was the long-delayed delivery of OpenAI's bare-metal SKUs - custom server configurations that would allow OpenAI to extract maximum performance from the hardware without the overhead of virtualization.
The work started around May 2024 with a target of Spring 2025, led by a Principal engineer who, according to Riet, had "evidently never tackled a task of that scale." The project ran into the same headwinds as everything else: an unstable software stack, insufficient testing infrastructure, organizational confusion, and the accumulated debt of years of deferred maintenance.
OpenAI's PM specs detailed ambitious demands, and Azure had made promises to meet them. Some requests for future bare-metal nodes required extensions to the Overlake card itself. Riet drafted these extensions and shared them with a Technical Fellow - a renowned kernel architect. The improvements could have been part of Overlake 4, with a software-only implementation deployable in the interim to enable fast system resets useful for AI research workflows.
None of it shipped in time. When OpenAI needed reliable, scalable compute, Azure could not deliver. CoreWeave could. Oracle could. The $11.9 billion deal, followed by the $6.5 billion expansion, followed by the $300 billion Oracle commitment - each was a vote of no confidence in Azure's ability to execute at the level its most important customer required.

What Happens Now
Riet's account ends with a question that hangs over the entire cloud industry: can Azure be fixed?
The structural problems he describes are not the kind that get solved with a reorg or a new initiative. The senior systems talent that built the original Fabric Controller has largely dispersed. The organizational culture has adapted to constant firefighting as normal operating procedure. The code base has grown so complex and interdependent that teams reject even simple refactoring for fear of breaking something.
Replacing or re-architecting a system of Azure's scale, Riet writes, is "like swapping an airplane's engines mid-flight. Not impossible in theory, but extremely risky in practice, especially when the crew has changed and the original expertise has mostly left."
For Azure customers, the implications are immediate. The node management stack that Riet describes - with its 173 agents, millions of monthly crashes, unencrypted tenant data cached in mixed memory, and web servers exposed to guest VMs on the privileged host - is running right now. It is running your workloads. It is running government workloads. It is running AI training jobs for models that millions of people rely on daily.
Microsoft has not yet responded to Riet's series. The company declined to make executives available for interviews when ProPublica investigated the digital escort program. Its emailed statement then said personnel operate "consistent with US Government requirements and processes." Whether that standard is sufficient is now a question for regulators, customers, and shareholders alike.
The hoofbeats are no longer a metaphor. They are financial results, customer defections, and a six-part confession from someone who was there when the system started to crack - and who tried, unsuccessfully, to stop it.
The trillion dollars is already gone. The question now is whether the next trillion follows.
Sources: Axel Riet, "How Microsoft Vaporized a Trillion Dollars" Parts 1-6, isolveproblems.substack.com (April 2, 2026). ProPublica, "A Little-Known Microsoft Program Could Expose the Defense Department to Chinese Hackers." CoreWeave press releases (March 2025, September 2025). Microsoft Azure documentation. Hacker News discussion thread #47616242.
Get BLACKWIRE reports first.
Breaking news, investigations, and analysis - straight to your phone.
Join @blackwirenews on Telegram