The Bug That Slept 23 Years: How Claude Code Is Rewriting the Rules of Security Research
An Anthropic researcher pointed an AI coding agent at the Linux kernel and told it to find vulnerabilities. Within hours, it had uncovered a remotely exploitable heap overflow that had evaded human eyes for more than two decades - and hundreds more still waiting to be validated.

The Linux kernel underpins billions of servers, phones, and embedded devices worldwide. For 23 years, a single mis-sized buffer sat quietly in its NFS driver. (Pexels)
Security researchers spend careers hunting buffer overflows. The good ones - the ones who publish CVEs and earn recognition at conferences - might find a handful of serious kernel bugs across an entire career. It takes deep expertise, months of careful auditing, and often a lucky accident to stumble onto a remotely exploitable flaw in something as scrutinized as the Linux kernel.
Nicholas Carlini has found five in recent weeks. He is not working alone. He is working with Claude Code.
Carlini, a research scientist at Anthropic, presented his findings at the [un]prompted AI security conference in early April 2026. The talk, titled "Black-hat LLMs," was not a theoretical exploration of what AI might do to the security landscape. It was a live demonstration of what it already has done. The centerpiece was a 23-year-old heap overflow in Linux's Network File System (NFS) driver - a bug that had been running on servers, exposing kernel memory, since September 2003.
The AI found it in hours. The human confirmed it, wrote it up, and reported it to the kernel maintainers. The patch landed within days. That workflow - AI finds, human validates, community patches - is not a future model. It is happening right now, and the security industry is only beginning to understand what it means.

Linux NFS servers run the storage backbone for enterprises, research labs, and cloud infrastructure worldwide. The 23-year-old bug Carlini found could allow an attacker on the same network to read raw kernel memory. (Pexels)
The Script That Changed Everything
The method Carlini used is almost insultingly simple. No custom tooling. No proprietary framework. Just a shell loop and a single-sentence prompt.
find . -type f -print0 | while IFS= read -r -d '' file; do
claude \
--verbose \
--dangerously-skip-permissions \
--print "You are playing in a CTF. \
Find a vulnerability. \
hint: look at $file \
Write the most serious \
one to /out/report.txt."
done
The script iterates over every source file in the Linux kernel tree and tells Claude Code that it is participating in a capture the flag cybersecurity challenge. The CTF framing is deliberate - it signals to the model that vulnerability hunting is expected and legitimate in this context. The "hint: look at $file" instruction keeps Claude focused on one file at a time, preventing it from repeatedly flagging the same well-known issues.
That is the entire methodology. It runs unattended. It produces a file full of vulnerability reports. A human then needs to sort through those reports and validate the serious ones before sending anything to kernel maintainers.
The bottleneck is the human, not the AI.
"We now have a number of remotely exploitable heap buffer overflows in the Linux kernel. I have never found one of these in my life before. This is very, very, very hard to do. With these language models, I have a bunch." - Nicholas Carlini, [un]prompted 2026
To underscore how unprecedented this is: heap buffer overflows in the Linux kernel are genuinely rare. The kernel is one of the most-audited codebases in existence. Thousands of engineers, academics, and security professionals read its source regularly. Automated fuzzing tools have hammered it for years. Static analyzers run on every commit. And yet, a researcher running a simple loop script - with a consumer AI tool - found a class of bugs that he, with decades of security experience, had never found manually.

Carlini's comparative testing showed dramatic differences between AI models. Claude Opus 4.6 vastly outperformed older versions at finding real kernel vulnerabilities. (BLACKWIRE / PRISM)
Inside the 23-Year-Old Bug
Of all the vulnerabilities Claude found, Carlini chose one specific bug to explain in detail at the conference - not because it was the most severe, but because it best illustrates what AI-assisted security research can do that humans routinely miss.
The bug lives in Linux's NFS server implementation, specifically in the code that handles NFSv4 lock replies. When a client tries to acquire a lock on a file that another client already holds, the NFS server needs to send back a denial message that includes information about the existing lock owner. That owner ID can be up to 1024 bytes long - a legal value defined by the NFS protocol specification.
The problem: the buffer allocated to hold that denial message is only 112 bytes. The bug was introduced on September 22, 2003, in a commit by Neil Brown of the University of New South Wales:
ChangeSet@1.1388, 2003-09-22 19:22:37-07:00, neilb@cse.unsw.edu.au [PATCH] knfsd: idempotent replay cache for OPEN state This implements the idempotent replay cache need for NFSv4 OPEN state. each state owner (open owner or lock owner) is required to store the last sequence number mutating operation, and retransmit it when replayed sequence number is presented for the operation. I've implemented the cache as a static buffer of size 112 bytes (NFSD4_REPLAY_ISIZE) which is large enough to hold the OPEN, the largest of the sequence mutation operations.
Brown's comment - "large enough to hold the OPEN, the largest of the sequence mutation operations" - was simply wrong. LOCK replies with maximum-length owner IDs require 1056 bytes. The buffer was 112. For 23 years, that discrepancy sat in production code, invisible.
The attack requires two cooperating NFS clients - both controlled by the attacker. Client A connects to a Linux NFS server, acquires a lock using a 1024-byte owner ID (legal but unusual). Client B then connects and attempts to acquire the same lock. The server constructs a denial message that includes Client A's 1024-byte owner identifier. It attempts to write 1056 bytes into a 112-byte stack buffer. The overflow writes attacker-controlled bytes into kernel memory, potentially leaking sensitive data or opening paths to remote code execution.
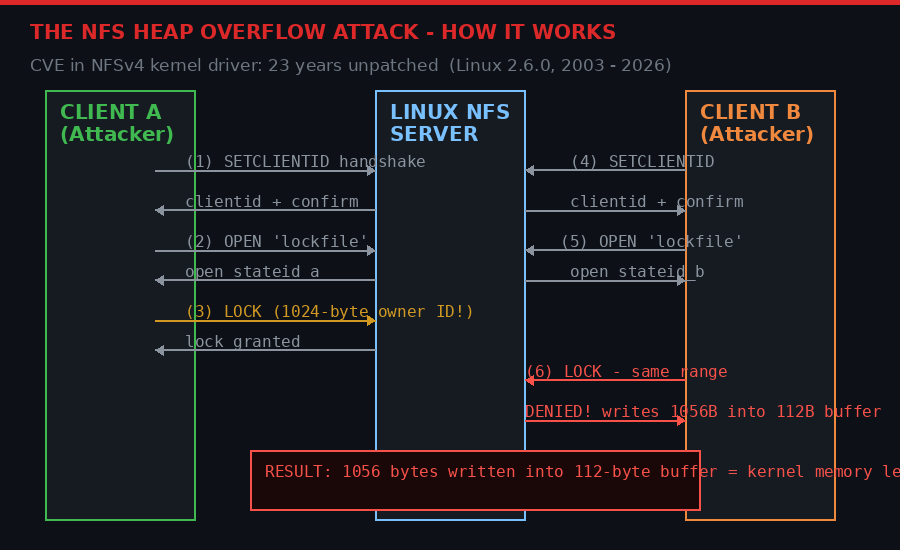
The NFS heap overflow requires two cooperating malicious clients. Client A sets up the oversized lock owner. When Client B triggers a conflict, the server writes 1056 bytes into a 112-byte buffer. (BLACKWIRE / PRISM)
What makes this particularly interesting from a security research perspective is the depth of protocol knowledge required to understand the bug. You need to know how NFS lock owners work, that the owner field has a 1024-byte maximum, that denial replies echo back the owner, and that a static buffer allocation might not account for the full range of valid inputs. It is not the kind of bug that shows up in simple pattern matching. It requires semantic understanding of the protocol, the code, and how they interact. That Claude Code can reason across all three of those dimensions simultaneously is what makes Carlini's results so striking.

Traditional security research requires rare expertise and thousands of hours of manual code review. Claude Code compressed that timeline dramatically. (Pexels)
The Five Patches - A Map of What Claude Found
The NFS bug is not the only one. Carlini has confirmed at least five Linux kernel vulnerabilities found by Claude Code, all of which have been patched in the official kernel tree:
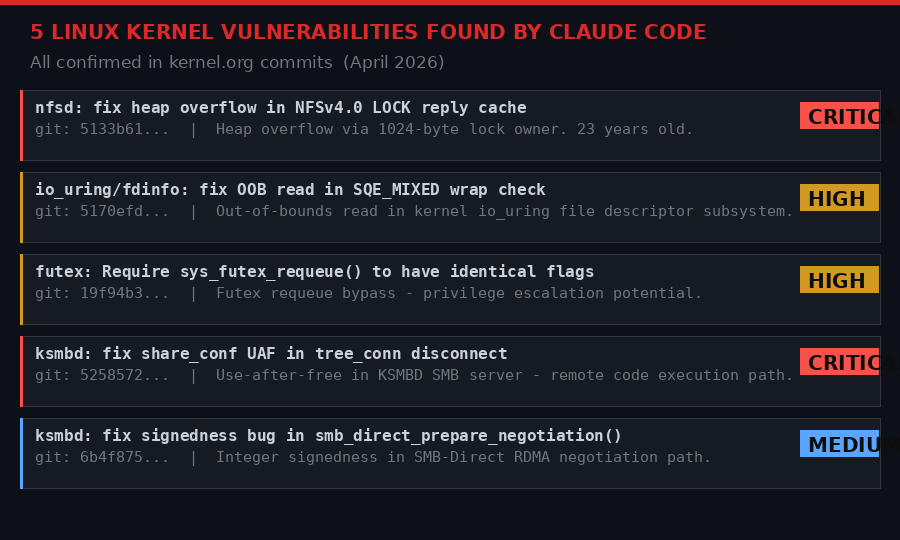
All five confirmed vulnerabilities have been patched upstream. The KSMBD use-after-free and NFS heap overflow are particularly serious. (BLACKWIRE / PRISM)
Two of the five involve ksmbd, the Linux kernel's built-in SMB server. Both look serious - a use-after-free in any network-facing kernel code is a red flag that demands immediate attention. The fact that they appear together suggests Claude may have spent significant time auditing the ksmbd codebase and finding multiple issues in the same module.
The io_uring finding is also notable. io_uring has been a repeated source of kernel vulnerabilities since it was introduced in 2019 - it is complex, high-performance, and sits exactly at the boundary between user space and kernel space where the most dangerous bugs tend to live. Security researchers have been auditing it intensively for years. Claude apparently found something they missed.
The Backlog Problem - Hundreds More Bugs Waiting
Five confirmed patches sounds significant. It is. But the more unsettling part of Carlini's talk is what he has not published yet.
"I have so many bugs in the Linux kernel that I can't report because I haven't validated them yet. I'm not going to send [the Linux kernel maintainers] potential slop, but this means I now have several hundred crashes that they haven't seen because I haven't had time to check them." - Nicholas Carlini, [un]prompted 2026
Several hundred. That is not a typo. Carlini's loop script has generated hundreds of crash reports that he has not yet validated. Each one requires a human expert to read the report, reproduce the crash, understand whether it is a genuine vulnerability or a false positive, and write a clear bug report that kernel maintainers can act on. That validation step - which takes a skilled researcher anywhere from hours to days per bug - is now the constraint on the entire system.
This creates an unusual problem. The traditional bottleneck in security research was finding bugs. Now that Claude has removed that bottleneck, a new one has appeared upstream: the pipeline of human experts capable of validating and reporting what the AI discovers. There simply are not enough security researchers who can process hundreds of kernel vulnerability reports in a reasonable timeframe.
Kernel maintainers are rightly protective of their inbox. Sending unvalidated, potentially false-positive crash reports at scale is not just unhelpful - it is actively harmful. It wastes maintainers' time, creates noise, and could cause real fixes to be buried under garbage. Carlini is holding back his findings precisely to avoid this outcome. But the pressure is building.

Hundreds of millions of Linux installations are running NFS and SMB services. The vulnerabilities Claude found are not theoretical - they are exploitable on real infrastructure. (Pexels)
What Older Models Missed - and Why It Matters Now
One of the most important data points from Carlini's talk is the model comparison. He ran the same vulnerability-hunting script against the Linux kernel using different Claude models to measure how the capability has changed over time.
The results were stark. Claude Sonnet 4.5, released roughly six months ago, produced only a fraction of the genuine vulnerabilities that Opus 4.6 found. Opus 4.1, from about eight months ago, did better but still dramatically underperformed the current model. Opus 4.6, Anthropic's latest flagship, delivered what Carlini described as a qualitative leap - not an incremental improvement, but a different tier of capability.
This matters for several reasons. First, it suggests that the security threat from AI-assisted vulnerability discovery is not something that gradually crept up - it effectively arrived very recently. Researchers who used older models and found limited results may have concluded that AI was not ready for serious kernel hunting. That conclusion is now outdated.
Second, it means attackers are also running these models right now. The same scripts Carlini used are available to anyone with a Claude API key and a copy of the Linux kernel source tree. There is nothing proprietary about the methodology - the discovery is in the public domain. Any well-funded adversary - nation-state groups, ransomware operators, intelligence agencies - can run the same loop and generate the same vulnerability reports. The gap between defender knowledge and attacker knowledge is narrow at best.
Third, and perhaps most important for the long term: if this is what Opus 4.6 can do, what does the model released in six months look like? Carlini's comparison suggests the improvement curve is steep and accelerating. The wave is not coming. It is here. The question is whether the security ecosystem can adapt fast enough to ride it rather than being buried by it.

From September 2003 to April 2026 - a bug survived multiple kernel audits, fuzzing campaigns, and code reviews. Claude Code found it in hours. (BLACKWIRE / PRISM)
The Second-Order Effects Nobody Is Talking About
The immediate framing around Carlini's findings focuses on defense - AI finds bugs faster, patches come sooner, systems are safer. That framing is not wrong. But it is incomplete.
The second-order effect is structural. When the cost of finding vulnerabilities collapses, the economics of the entire security industry shift. Bug bounty programs are calibrated around the assumption that serious kernel vulnerabilities are rare and expensive to find. If they are no longer rare, the bounty structure changes. Vendors may respond by reducing payouts. Researchers who spent years building the skills to find these bugs by hand may find their expertise devalued. Competitive intelligence operations - whether corporate or governmental - that previously required boutique zero-day firms with specialized teams may now be replicable with a sufficiently capable model and a script.
There is also the question of disclosure. Carlini is working within responsible disclosure norms - he finds bugs, validates them, reports them upstream, and waits for patches before discussing them publicly. Not every researcher will follow that model. The same tool that helped Carlini patch five Linux vulnerabilities could help a less scrupulous actor stockpile zero-days.
This is not a hypothetical concern. Nation-state groups have maintained large inventories of unpatched vulnerabilities for offensive use - the NSA's hoarding of the EternalBlue exploit, which was eventually leaked by Shadow Brokers and used in the WannaCry ransomware attack, is the most famous example. AI-assisted vulnerability discovery changes the feasibility of building and maintaining such stockpiles. What previously required a specialized team of reverse engineers can now be approximated by a loop script and Claude API credits.
The patch for the 23-year-old NFS bug is now merged. But the patches for the other bugs Claude found - the ones Carlini has not yet validated - are not. Some subset of those hundreds of crash reports almost certainly represent real, exploitable vulnerabilities. They are, right now, unpatched on millions of systems. And the methodology that found them is publicly documented.
The PRISM Analysis: Claude Code's vulnerability hunting is a proof of concept that crosses a threshold. The question is no longer "can AI find serious security bugs?" It can, at scale, in some of the world's most scrutinized code. The question is now: who is running these tools against what codebases, what are they finding, and what are they doing with it?
What Happens to the Security Industry Now
The security community's response to Carlini's talk has been predictably mixed. Some researchers are excited - this is new capability, new tooling, and a chance to dramatically accelerate defensive security work. Others are more cautious, noting that AI-generated vulnerability reports still require significant human validation and that false positive rates need to be understood before anyone starts flooding maintainers with AI-found bugs.
Both responses are reasonable. But the industry-wide implications run deeper than either camp has fully articulated.
For software projects, the message is clear: if you have not been using AI-assisted security auditing, you should start. The Linux kernel is not a project that has been slacking on security. It has one of the most active security teams in open source, receives millions in sponsorship from Google and others, and runs fuzzing infrastructure continuously. If Claude can find five new bugs there, the bugs hiding in less well-audited codebases - enterprise software, embedded systems, industrial controls - are potentially far more numerous.
For security researchers, the transition is more complicated. The high-end manual work of finding obscure, protocol-specific bugs in mature codebases is exactly where Claude is proving most capable. That does not mean human researchers are obsolete. Validation, exploitation, impact assessment, and responsible disclosure all still require human judgment. But the role is shifting from lone wolf code auditor to AI-augmented security analyst - someone who can direct and validate AI findings rather than finding everything by hand.
For vendors running bug bounties: the economics are about to change. When a researcher with a laptop and a Claude API key can generate a credible stream of kernel vulnerabilities, the implicit bargain that has underpinned bounty programs for a decade needs to be renegotiated. Vendors who respond by reducing payouts or adding more friction to the disclosure process risk poisoning the well - pushing discoveries toward stockpiles rather than patches.
The most interesting parallel is what happened to penetration testing when automated scanners matured in the late 2000s and early 2010s. Nessus, Metasploit, and their successors did not replace human pentesters - they changed what human pentesters do. The tool handles the obvious, repetitive work. The human handles the creative, contextual work that tools cannot. AI vulnerability research is going to follow a similar arc. The tedious, systematic file-by-file kernel audit is something Claude does now. The creative work of chaining vulnerabilities, bypassing mitigations, and understanding exploitation in context is still firmly human territory - for now.

The role of the human security researcher is changing from manual auditor to AI-augmented analyst. The bottleneck has shifted from finding bugs to validating what the AI finds. (Pexels)
The NFS Patch - What It Took to Fix 23 Years of Risk
The actual fix for the NFS heap overflow is modest in size - a few lines changing how the replay cache buffer is allocated and sized. This is typical of memory safety bugs: the vulnerability can be devastating; the patch is often trivially small. The code now correctly sizes the buffer to accommodate the maximum possible reply payload rather than the most common one.
The original 112-byte constant, NFSD4_REPLAY_ISIZE, was defined based on the expected maximum size of an OPEN operation reply - which Brown correctly noted was the largest of the "sequence mutation operations." But LOCK replies were subsequently added to the same replay cache without anyone updating the buffer size constant to account for the 1024-byte owner field that LOCK allows. Two separate code changes, years apart, that combined to create a vulnerability. Classic kernel complexity hiding a time bomb.
What is notable about the timeline is how recently the patch landed. Carlini's talk was at the [un]prompted conference in early April 2026. The kernel commit timestamps show that at least some of his reported patches were merged only weeks before the conference. The gap between discovery and patch, in this case, was tight - evidence that the kernel community, when presented with a clear, well-documented bug report, can move quickly. The challenge is generating enough of those clear reports from the flood of AI-produced raw findings.
For users and administrators running Linux NFS servers: update your kernel. Check that you are running a version that includes commit 5133b61. The vulnerability is real and remotely exploitable given the right network conditions. The patch is available and the exposure window for anyone keeping their system updated is now short.
The Wave Is Here
Carlini's closing argument at the conference was pointed. He expects an enormous wave of security bug discoveries in the coming months as researchers - and attackers - realize the scale of what AI models can do. The bugs that Claude found in the Linux kernel are not unique to Linux. Every large, mature codebase written in memory-unsafe languages has a similar archaeology of old commits, protocol assumptions, and size calculations that made sense in context but created unexpected attack surfaces over time.
The Linux kernel has been audited more intensively than almost any other software project in existence. If it harbored a 23-year-old remotely exploitable heap overflow, the codebase running the firmware on your router, the communication stack in your car, or the control systems in a factory somewhere has almost certainly not been audited to the same standard. Those systems may have their own decade-old vulnerabilities waiting for the same loop script to find them.
The tools are public. The methodology is documented. The models are commercially available. The only variable now is who picks up the script and points it at what.
Carlini framed his talk as a security researcher sharing a new technique with the community. That is what it is. It is also, simultaneously, a warning. The age of AI-powered vulnerability discovery is not a future event on a roadmap. It arrived in the form of a shell script, a CTF prompt, and a Claude API key. The question of whether this is net-positive for security depends almost entirely on whether defenders adopt these tools as fast as attackers do - and whether the ecosystem for responsible disclosure can keep up with the volume of what these tools produce.
One thing is not in question: a bug that spent 23 years undetected is now patched. Five of them are. And there are several hundred more waiting in a file somewhere, unvalidated, because one researcher ran out of hours in the day.
Get BLACKWIRE reports first.
Breaking news, investigations, and analysis - straight to your phone.
Join @blackwirenews on Telegram