GPU Rowhammer: Three New Attacks Give Full Root Access to Cloud Machines via Nvidia Hardware
Three independent research teams just demonstrated that the 12-year-old Rowhammer memory attack technique works against Nvidia GPU GDDR6 memory - and can hand an unprivileged cloud tenant complete root control of a shared server. One attack bypasses the primary mitigation entirely.
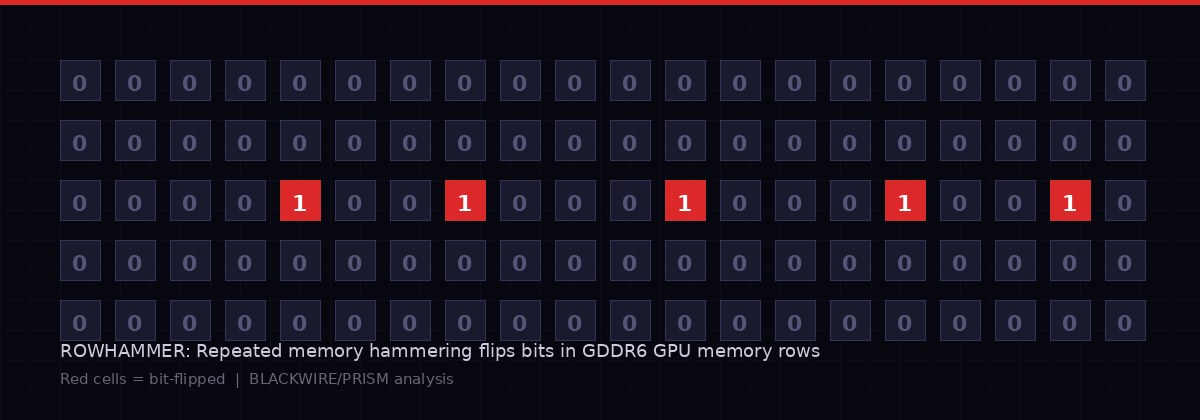
Visualization of Rowhammer-induced bit flips in GDDR6 GPU memory. Repeated hammering of adjacent rows creates electrical disturbances that flip stored bits - a phenomenon researchers have now weaponized against Nvidia's most widely deployed GPU hardware. BLACKWIRE/PRISM
The cloud computing model runs on a dangerous assumption: that tenants sharing hardware cannot touch each other. Twelve years of Rowhammer research have been slowly eroding that assumption in CPU memory. This week, three independent research teams finished the job on the GPU side.
On Thursday and Friday, April 3-4, 2026, academic researchers published details of three novel attacks - GDDRHammer, GeForge, and GPUBreach - that demonstrate GPU Rowhammer exploitation against Nvidia Ampere-generation cards, achieving something no prior attack had accomplished: complete root-level compromise of the host machine, starting from an unprivileged user sharing a GPU in a cloud environment.
The practical implication lands hardest for AI workloads. Every major cloud provider sells GPU-accelerated compute to multiple tenants simultaneously. An attacker renting a few hours of compute time on a shared Nvidia RTX 3060 or RTX A6000 can now, under the right conditions, gain read and write access to the host's entire physical memory - including the model weights, training data, API keys, and cryptographic material belonging to every other tenant on that machine.
The third attack, GPUBreach, goes further still. It works even when the primary recommended mitigation - enabling IOMMU - is active. There is currently no complete software fix.
What Is Rowhammer and Why Does It Matter for GPUs
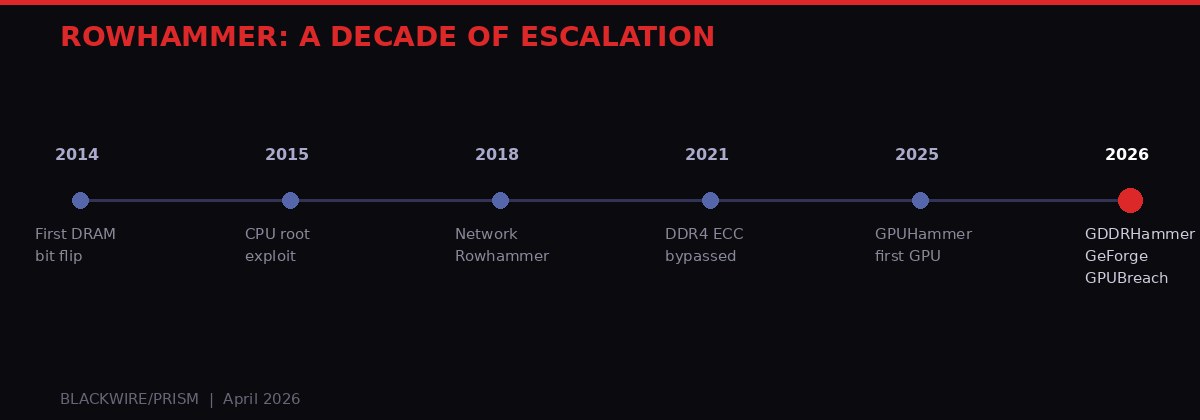
Rowhammer's decade-long evolution from a theoretical curiosity to a GPU-capable threat. Each generation of hardware brought new defenses; each generation of researchers found ways around them. BLACKWIRE/PRISM
Rowhammer is not a software bug. It is a physical property of how DRAM memory cells are manufactured. When a processor reads from a specific row of memory cells repeatedly and rapidly - "hammering" it - the electrical disturbance bleeds into adjacent rows and flips stored bits. A 0 becomes a 1. A 1 becomes a 0. In most contexts this is a random corruption. But with precise knowledge of memory layouts, an attacker can target specific bits in specific data structures and force predictable, controllable changes.
The attack was first documented in 2014 by researchers at Carnegie Mellon University (Kim et al., ISCA 2014). By 2015, Google Project Zero had turned it into a practical privilege escalation exploit on CPUs, rooting Linux machines by flipping bits in page table entries. Over the next decade, the technique expanded to cover DDR4, ECC-protected memory, network-accessible DRAM, and mobile devices running Android.
Each hardware generation brought new defenses: Target Row Refresh (TRR), ECC (Error Correcting Codes), and eventually IOMMU-based memory isolation. Each defense held for a while - until researchers found ways around it. The pattern has been consistent: hardware vendors ship products with inadequate Rowhammer protections, academics demonstrate the exploits, vendors patch, repeat.
Graphics memory - GDDR - was long considered a separate domain. GPUs use GDDR rather than DDR memory, the electrical characteristics are different, and the access patterns are more sequential than the random row-hammering CPUs are subject to. When a team demonstrated the first GPU Rowhammer attack in 2025 (GPUHammer), achieving only eight bit flips with limited impact - degrading neural network output without achieving privilege escalation - it looked like GDDR might be a harder target.
This week's papers definitively closed that door.
The Three Attacks: Technical Breakdown

Technical comparison of the three GPU Rowhammer attacks published April 3-4, 2026. GPUBreach is the most dangerous - it bypasses IOMMU, the primary recommended mitigation for the other two. Source: Ars Technica / gddr.fail / GPUBreach.ca
Three teams, working independently, converged on the same fundamental insight: GDDR6 memory in Nvidia Ampere-generation GPUs can be hammered with enough precision and volume to corrupt GPU page tables - and those corrupted page tables can be leveraged to access host CPU memory.
GDDRHammer
The first attack, presented in the paper "GDDRHammer: Greatly Disturbing DRAM Rows - Cross-Component Rowhammer Attacks from Modern GPUs," targets the Nvidia RTX A6000 from the Ampere architecture generation. The "GDDR" in the name stands for both "Graphics DDR" and "Greatly Disturbing DRAM Rows."
GDDRHammer induced an average of 129 bit flips per memory bank - a 64-fold increase over the previous GPUHammer work (2025), which achieved only eight bit flips total. That improvement is not just statistical. It crosses the threshold required for reliable exploitation.
"Our work shows that Rowhammer, which is well-studied on CPUs, is a serious threat on GPUs as well. With our work, we show how an attacker can induce bit flips on the GPU to gain arbitrary read/write access to all of the CPU's memory, resulting in complete compromise of the machine." - Andrew Kwong, co-author, GDDRHammer
The key innovation is a technique called memory massaging - a process of manipulating the GPU's memory allocator to move sensitive data structures (specifically GPU page tables) out of protected memory regions and into regions vulnerable to Rowhammer. Nvidia's GPU driver stores page tables in reserved low-memory by design. GDDRHammer circumvents this by first using Rowhammer to flip bits that control which memory regions are allocated as protected - effectively unlocking the door before picking it.
Once page table entries are in a hammerable region, the attack corrupts specific entries to grant the attacking process arbitrary read and write access to GPU memory. From there, it leverages the GPU's "system aperture" mappings - the mechanism that allows GPU code to access CPU physical memory - to read and write to the host's entire address space. Root shell follows.
GeForge
The second attack - "GeForge: Hammering GDDR Memory to Forge GPU Page Tables for Fun and Profit" - works against both the RTX 3060 and RTX 6000, and achieves a substantially higher bit flip count: 1,171 flips against the RTX 3060 and 202 flips against the RTX 6000.
Where GDDRHammer targets the last-level page table, GeForge attacks the last-level page directory. The practical effect is similar: corruption of GPU address translation structures that enables the attacker to redirect memory access to attacker-controlled space. The proof-of-concept exploit against the RTX 3060 concludes with the opening of a root shell on the host Linux machine.
"By manipulating GPU address translation, we launch attacks that breach confidentiality and integrity across GPU contexts. More significantly, we forge system aperture mappings in corrupted GPU page tables to access host physical memory, enabling user-to-root escalation on Linux. To our knowledge, this is the first GPU-side Rowhammer exploit that achieves host privilege escalation." - GeForge paper authors
Both GDDRHammer and GeForge require IOMMU to be disabled. This is the default configuration in most BIOS settings - disabled for compatibility reasons and because enabling IOMMU imposes performance overhead from address translation operations. The practical implication: most cloud-deployed GPU servers, shipped with default BIOS settings optimized for throughput, are vulnerable right now.
GPUBreach: The One That Bypasses the Fix
If GDDRHammer and GeForge represent serious threats, GPUBreach is the scenario that keeps cloud security architects awake at night. Published Friday April 4 - one day after the first two papers - it achieves the same root-shell outcome, but with a crucial difference: it works even when IOMMU is enabled.
The attack takes a different approach. Rather than corrupting GPU page tables to forge memory access through aperture mappings, GPUBreach exploits memory-safety bugs in the Nvidia GPU driver itself.
"By corrupting GPU page tables, an unprivileged CUDA kernel can gain arbitrary GPU memory read/write, and then chain that capability into CPU-side escalation by exploiting newly discovered memory-safety bugs in the NVIDIA driver. The result is system-wide compromise up to a root shell, without disabling IOMMU, unlike contemporary works, making GPUBreach a more potent threat." - GPUBreach research team, gpubreach.ca
The mechanism: when IOMMU is enabled, it confines the GPU's direct memory access to driver-owned buffers. GPUBreach accepts that confinement - but then corrupts metadata within those permitted buffers. The GPU driver, running at kernel privilege on the CPU, processes that corrupted metadata and performs out-of-bounds writes that the attacker controls. IOMMU is never bypassed directly; instead, the attack turns the driver itself into a weapon, using it to write arbitrary data to kernel memory.
This is a fundamentally different attack class. IOMMU can defend against a GPU directly accessing CPU memory. It cannot defend against a compromised GPU driver doing the same thing. The mitigation pyramid collapses.
Memory Massaging: How Attackers Put Bits in the Right Place
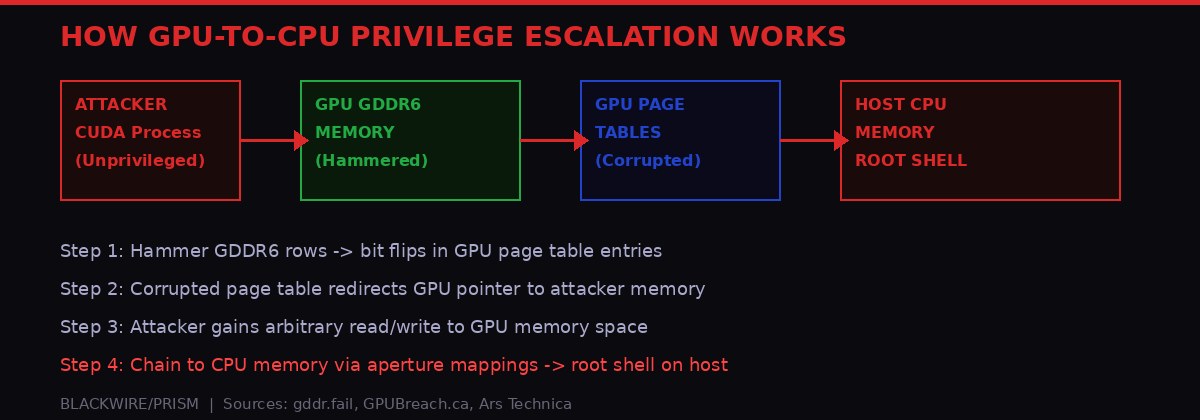
The exploit chain: hammering GDDR6 flips bits in GPU page tables, corrupting them to redirect memory access to attacker-controlled space. The attack then chains into full host CPU memory access and a root shell. BLACKWIRE/PRISM
All three attacks rely on memory massaging to make bit flips land in useful locations. This is the most technically sophisticated part of the work, and understanding it clarifies why these attacks are not theoretical demonstrations that only work in controlled lab conditions.
The core problem: Rowhammer doesn't let you choose which specific bits to flip. It depends on the physical layout of memory rows. An attacker hammers specific rows, but which bits flip depends on where the target data happens to be stored in physical memory. If the GPU driver protects page tables by storing them in reserved regions that can't be flipped, the attack stalls.
Memory massaging is the process of manipulating memory allocation to coerce the operating system or GPU driver into placing target data structures in physical memory regions the attacker can hammer. For GDDRHammer, this involves Rowhammering the bits that control which memory regions are designated as protected - bootstrapping the attack by first using bit flips to unlock the region needed for subsequent bit flips.
Researcher Zhenkai Zhang described the GeForge massaging process in precise terms:
"We first isolate the 2 MB page frame containing the steering destination. We then use sparse UVM accesses to drain the driver's default low-memory page-table allocation pool and free the isolated frame at exactly the right moment so it becomes the driver's new page-table allocation region. Next, we carefully advance allocations so that a page directory entry lands on the vulnerable subpage inside that frame. Finally, we trigger the bit flip so the corrupted page directory entry redirects its pointer into attacker-controlled memory, where a forged page table can be filled with crafted entries." - Zhenkai Zhang, GeForge co-author
This level of precision - draining allocation pools, timing frees to capture specific frames, placing data structures in hammerable positions - represents years of reverse-engineering the Nvidia GPU driver's internal memory management. It is not something casual attackers develop overnight. But once documented in a research paper with proof-of-concept code, the barrier drops significantly. Security researchers and offensive security tooling developers will have working implementations within weeks.
The Cloud Attack Surface
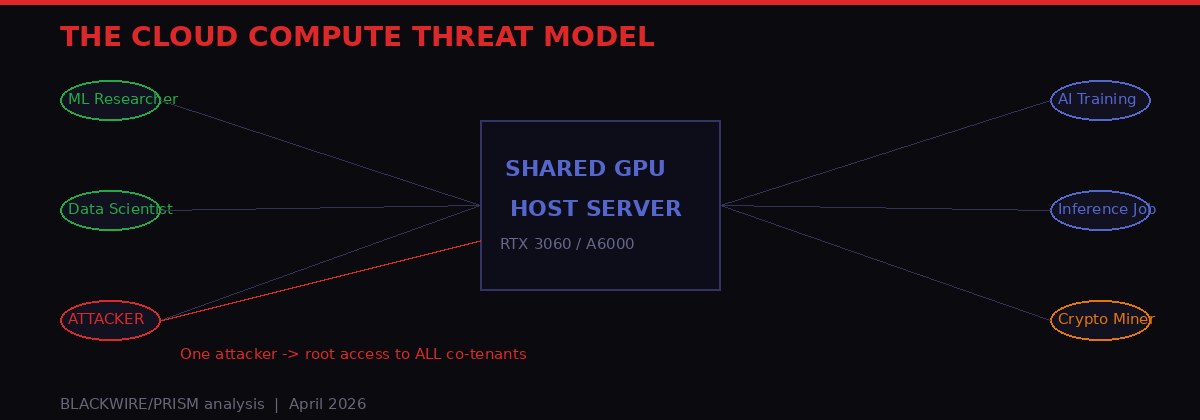
In shared cloud GPU environments, a single malicious tenant can gain root access to the physical host server - exposing the memory, data, and workloads of every other co-tenant. BLACKWIRE/PRISM
The academic papers test their exploits in single-machine environments where the attacker controls the attacking process directly. Cloud deployments change the threat model in ways that matter considerably.
High-performance GPUs - typically $8,000 or more per unit at enterprise prices - are almost universally shared in cloud environments. AWS, Google Cloud, Lambda Labs, CoreWeave, and dozens of smaller providers slice GPU time among multiple tenants to make the economics work. A typical Nvidia A6000 in a cloud environment might be serving four to eight paying customers simultaneously, each running their own CUDA workloads in what they believe are isolated containers or virtual machines.
The Rowhammer attack does not respect those isolation boundaries. Once an attacker gains root access to the host machine via GPU Rowhammer, every co-tenant on that physical server is exposed. Their data is readable. Their processes can be manipulated. Their credentials can be harvested. This is not a theoretical edge case - it is the fundamental cloud compute model applied to a hardware-level vulnerability.
Which Cards Are Confirmed Vulnerable?
- RTX A6000 (Ampere): Vulnerable to GDDRHammer and GPUBreach
- RTX 3060 (Ampere): Vulnerable to GeForge - 1,171 bit flips demonstrated
- RTX 6000 (Ampere): Vulnerable to GDDRHammer and GeForge
- Ada Lovelace generation: Not tested. GDDRHammer team did not reverse-engineer the newer GDDR variant. Status unknown, not cleared.
- Hopper generation (H100/H200): Not studied. Vulnerability status unknown.
The Ada Lovelace and Hopper caveats deserve emphasis. The GDDRHammer researchers note that the RTX 6000 Ada model uses a newer form of GDDR that their team did not reverse-engineer, meaning it was not tested. This does not mean Ada is safe. It means Ada has not been studied yet. Twelve years of Rowhammer history suggest that "unstudied" and "invulnerable" are not synonymous.
The H100 and H200 - Nvidia's flagship datacenter GPUs, the backbone of hyperscale AI training - have similarly not been evaluated. Every major AI lab training frontier models on H100/H200 clusters is operating hardware whose Rowhammer status is unknown. That is not a comfortable position given this week's disclosures.
IOMMU: The Incomplete Fix

IOMMU controls whether the GPU can directly access CPU address space. Enabling it closes GDDRHammer and GeForge - but GPUBreach circumvents it by targeting driver-level memory safety bugs instead. BLACKWIRE/PRISM
The standard recommended mitigation for GDDRHammer and GeForge is enabling IOMMU in BIOS. IOMMU - Input-Output Memory Management Unit - is a hardware component that manages virtual-to-physical memory address translations for devices like GPUs. When properly configured, it prevents a GPU from directly accessing sensitive memory regions on the host CPU.
"In the context of our attack, an IOMMU can simply restrict the GPU from accessing sensitive memory locations on the host. IOMMU is, however, disabled by default in the BIOS to maximize compatibility and because enabling the IOMMU comes with a performance penalty due to the overhead of the address translations." - Andrew Kwong, GDDRHammer
The performance overhead is real and non-trivial. For GPU-intensive workloads - machine learning training, scientific computing, inference serving - IOMMU address translation overhead can reduce effective throughput by several percent. For cloud providers operating at scale with thin margins, this is not a cost-free decision. Many choose to disable IOMMU for competitive performance reasons, and the vulnerability's default-on nature means most production systems are currently exposed.
But even setting aside performance questions, IOMMU is not a complete defense. GPUBreach was specifically designed to work around it. The attack exploits memory-safety bugs in the Nvidia GPU driver itself - and since the driver runs at kernel privilege on the CPU, IOMMU confinement of GPU memory access is irrelevant. The exploit does not need the GPU to directly access CPU memory. It poisons the driver with crafted GPU-side memory structures, then waits for the driver to perform the malicious writes on the GPU's behalf.
ECC (Error Correcting Codes) on GPU memory is a second potential mitigation. Nvidia allows ECC to be enabled via command line:
ECC can detect and correct some single-bit errors, potentially stopping Rowhammer bit flips before they take effect. However, the research record on ECC as a Rowhammer defense is mixed. Numerous prior attacks have demonstrated ECC bypass techniques, and the current research papers do not comprehensively evaluate ECC effectiveness against these specific GPU attacks. Enabling ECC also reduces total available GPU memory by approximately 6-12%, which matters for memory-intensive AI workloads already running near card capacity.
Second-Order Effects: AI Workloads in the Crosshairs

The attack surface extends well beyond a root shell. Cloud AI workloads carry high-value data in CPU memory that becomes fully accessible once privilege escalation completes. BLACKWIRE/PRISM
Security discussions around these attacks tend to focus on the root shell - the visible endpoint of the exploit chain. The more consequential threat may lie in what an attacker can do with arbitrary read access to host CPU memory before anyone notices anything is wrong.
AI model training workloads are particularly exposed. A language model training run continuously loads model weights, optimizer state, gradient buffers, and training data batches into CPU and GPU memory. An attacker co-tenant who achieves CPU memory read access gains access to all of this material for as long as the training run shares the physical hardware. The access is invisible at the application layer. There are no failed login attempts, no unusual API calls, no network anomalies. The data simply gets read.
Model weights for large language models represent months of compute time and hundreds of millions of dollars of investment. The ability to silently exfiltrate those weights - without triggering any alerting, without any visible intrusion in application-layer logs - represents a competitive intelligence threat that goes well beyond typical enterprise data breach scenarios. For AI labs training proprietary frontier models, this attack class represents potential existential competitive risk.
Training data carries different but equally serious risks. Healthcare organizations fine-tuning medical AI models on patient data load those records into memory during preprocessing. Financial institutions running fraud detection models process transaction history in shared compute environments. Academic research groups working on genomics or clinical trial data have similar exposure. All of it lands in the shared memory space of a physical server that an attacker with a few dollars of compute credit can target.
Inference workloads face a different threat vector. The ability to write to CPU memory - not just read - enables an attacker to inject adversarial inputs into another tenant's inference pipeline without any application-layer access. A model serving responses to legitimate users could be silently poisoned to produce specific incorrect outputs, with no indication that the tampering is occurring at any layer the legitimate operator monitors.
API keys and authentication tokens stored in memory of running processes are trivially extractable once root is achieved. Cloud AI service credentials - for OpenAI APIs, Anthropic APIs, Google Cloud AI services, proprietary model serving infrastructure - routinely live in environment variables and configuration files loaded into process memory. A compromised host server makes all of those credentials available to whoever is running the attack.
What Nvidia Said - and What It Did Not
Nvidia's public response to the first two attacks was minimal. An Nvidia representative directed users to a security advisory page published in July 2025 in response to the original GPUHammer work, declining to elaborate on whether new patches are in development or what specifically covers the 2026 attacks.
The existing advisory (nvidia.custhelp.com/app/answers/detail/a_id/5671) addresses the previous generation of GPU Rowhammer research from 2025. Whether it applies to GDDRHammer, GeForge, and GPUBreach - particularly GPUBreach's driver-level exploitation - is not clarified in Nvidia's current communications.
Nvidia Guidance Gap
Nvidia's current public advisory (nvidia.custhelp.com/app/answers/detail/a_id/5671) was written in response to the 2025 GPUHammer work and does not specifically address GDDRHammer, GeForge, or GPUBreach published April 3-4, 2026. The lack of updated guidance creates ambiguity about which driver versions contain fixes for the driver-level bugs exploited by GPUBreach. Cloud providers and sysadmins should not assume the existing advisory provides coverage for the 2026 attack generation.
This silence matters most for GPUBreach. Unlike the other two attacks, which require hardware-level conditions (IOMMU disabled, specific GDDR properties), GPUBreach exploits code. Code bugs get patched. But Nvidia has not confirmed a patch timeline, specified the driver versions affected, or clarified whether GPUBreach requires separate CVE assignment beyond the 2025 guidance. The longer that gap persists, the longer production systems remain fully exposed to the IOMMU-bypassing variant.
Mitigation Guide: What Sysadmins Should Do Now

Current mitigation options and their coverage against each known attack variant. No single mitigation stops all three. A layered approach is required. BLACKWIRE/PRISM
Complete protection does not currently exist. GPUBreach has no confirmed patch. That said, the following steps materially reduce exposure and should be treated as high priority for any deployment using Nvidia Ampere-generation GPUs in shared or multi-tenant environments.
Enable IOMMU in BIOS
This is the most impactful single step for GDDRHammer and GeForge. In BIOS, look for settings labeled "IOMMU," "VT-d" (Intel platforms), or "AMD-Vi" (AMD platforms) and enable them. The performance cost is real - expect several percent overhead on memory-intensive GPU workloads - but the security benefit outweighs it for production AI serving infrastructure where data sensitivity is high.
On Linux, verify IOMMU is active after enabling it in BIOS:
Enable ECC on GPU
ECC provides an additional layer of protection against single-bit errors. Note the memory capacity reduction and reboot requirement:
For memory-constrained workloads running near card capacity, the 6-12% memory reduction may require adjusting batch sizes or model serving configurations. Evaluate against your workload before deploying in production.
Monitor for Anomalous GPU Memory Access Patterns
Rowhammer attacks require sustained high-frequency row access - hammering specific memory rows thousands of times per second. This pattern is anomalous relative to legitimate workloads. GPU performance counter monitoring can potentially detect it. No off-the-shelf detection tool exists specifically for GPU Rowhammer, but baselining normal workload access patterns and flagging deviations is viable for high-security environments with engineering resources.
Review Tenant Co-Location Policies
Cloud providers with flexibility over workload placement should review whether AI training runs carrying proprietary model weights or sensitive training data are co-located on the same physical GPU as untrusted tenants. Dedicated GPU instances - one tenant per physical card - eliminate the cross-tenant attack vector entirely. The cost premium is real but may be warranted for high-sensitivity workloads.
Accelerate Hardware Generation Evaluation
The confirmed vulnerable cards are from Nvidia's Ampere generation (2020): RTX 3060, RTX 6000, RTX A6000. Organizations running these in multi-tenant environments should treat this week's disclosures as a prompt to accelerate evaluation of Ada Lovelace or Hopper generation hardware. Not because those are confirmed safe - they have not been studied - but because reducing exposure to confirmed vulnerable hardware is a straightforward risk management step while the research community catches up.
The Bigger Picture: Hardware Security in the Age of AI
The timing of these disclosures is not coincidental. GPU-accelerated computing has moved from gaming curiosity to foundational layer of the global AI industry in under five years. The economic value concentrated in GPU memory has grown correspondingly. An attack that was a theoretical demonstration of memory physics in 2014 is now a potential competitive espionage tool aimed at trillion-dollar AI investments.
The Rowhammer research community has been running ahead of hardware defenses for a decade. Each memory generation brought new defenses; each brought new attacks. The pattern suggests a structural problem: DRAM and GDDR physics create an inherent vulnerability in how memory cells interact at the hardware level. ECC helps. IOMMU helps. Neither is sufficient against a determined researcher with a novel approach, and the researchers keep arriving.
The GPU-specific dimension adds a new layer. CPU Rowhammer has driven a significant body of defensive work - hardware Target Row Refresh, software-based access frequency mitigations, ECC integration improvements. GPU memory defense is essentially 12 years behind that curve. GPU vendors designed GDDR primarily for throughput, bandwidth, and energy efficiency. Security against Rowhammer was not a design requirement. It is one now.
For the AI industry specifically, the implications run deeper than a set of CVEs to patch. The cloud GPU model - shared hardware, multi-tenant isolation, cryptographic and container-based separation - has an underlying hardware vulnerability that software-layer security cannot fully address. Three independent research teams converging on the same exploit class in the same week suggests the problem is well-understood in the academic community. It should be equally well-understood in the security teams of every organization running sensitive AI workloads on shared GPU infrastructure.
The three research teams have published their papers publicly, with proof-of-concept code available or forthcoming. The window between "known to academics" and "in the toolkit of sophisticated attackers" is measured in weeks, not months. Nvidia and the cloud providers do not have time for slow patch cycles on this one.
Get BLACKWIRE reports first.
Breaking news, investigations, and analysis - straight to your phone.
Join @blackwirenews on Telegram