Google Gemma 4: The Open-Source AI Model That Changes Everything
Google killed its restrictive custom license, shipped four models under Apache 2.0, and landed at #3 on the global open-model leaderboard. With 400 million downloads behind the Gemma family and a new architecture that runs frontier-class intelligence on a Raspberry Pi, this is the moment open-source AI stopped being second-class.

The open-source AI landscape shifted overnight when Google dropped its licensing restrictions. Photo: Unsplash
Google DeepMind just did something it has never done before: it surrendered control.
On April 2, 2026, the company released Gemma 4 - four open-weight AI models built from the same technology as its proprietary Gemini 3 system - under the Apache 2.0 license. That last detail matters more than every benchmark number combined. For the first time in the Gemma family's existence, developers can use, modify, and commercially deploy these models without worrying that Google might change the rules tomorrow.
The timing is not coincidental. The open-model ecosystem has exploded over the past year, with DeepSeek, Alibaba's Qwen, Z.ai's GLM, and Moonshot's Kimi all claiming territory on performance leaderboards while shipping under permissive licenses. Google's previous Gemma 3, released over a year ago, used a custom license that let the company update terms unilaterally and potentially claimed rights over synthetic data generated by the model. Developers noticed. Many stayed away.
Now Google is playing catch-up on openness while trying to leapfrog on capability. The result is a release that will reshape how developers think about running AI locally, what "open-source AI" actually means, and whether the cloud-first model of AI deployment has a shelf life.

The Gemmaverse by the numbers - 400 million downloads and 100,000+ community variants. BLACKWIRE PRISM
The Four Models: From Datacenter to Pocket

Gemma 4's larger models run on a single H100 GPU - still enterprise hardware, but a fraction of what competing models demand. Photo: Unsplash
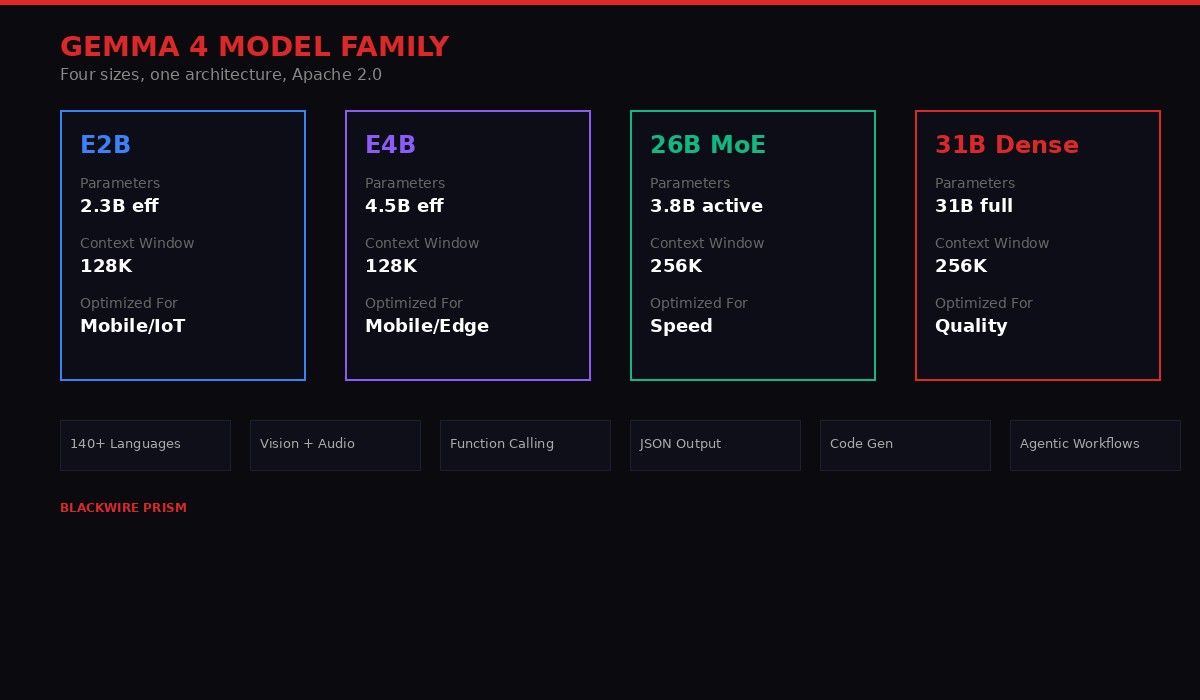
Gemma 4 ships in four sizes, and the design philosophy behind each reveals Google's strategy: cover every deployment scenario from cloud clusters to smartphones, and make each model the best in its weight class.
The flagship is the 31B Dense model. All 31 billion parameters activate during every inference pass, making it the quality champion of the family. It currently ranks #3 on the Arena.ai open-source text leaderboard with an ELO score of 1452, sitting behind only Z.ai's GLM-5 (1456) and Moonshot's Kimi 2.5 (1453). For context, the models above it are significantly larger - GLM-5 runs at 12 billion-plus parameters with substantially more compute overhead. Gemma 4 31B delivers comparable intelligence at a fraction of the infrastructure cost.
The unquantized bfloat16 weights fit on a single 80GB NVIDIA H100 GPU. That is a $20,000 accelerator, so "accessible" is relative. But quantized versions run on consumer GPUs - an RTX 4090 or even an M2 MacBook Pro with sufficient RAM can handle it. A year ago, hitting this tier of performance required multi-GPU setups or cloud API calls. Now it fits on hardware a freelance developer might already own.
The 26B Mixture of Experts (MoE) model takes a different approach to the speed-versus-quality tradeoff. It contains 26 billion total parameters but activates only 3.8 billion during inference. This architecture, where different "expert" subnetworks handle different types of inputs, means dramatically faster token generation. It ranks #6 on Arena.ai with an ELO of 1441 - competitive with the dense model but with throughput that makes real-time applications practical. For developers building chatbots, coding assistants, or agentic systems where latency matters more than marginal quality gains, this is the model to watch.
Gemma 4's four-model family covers everything from IoT devices to datacenter GPUs. BLACKWIRE PRISM
Then there are the edge models: Effective 2B (E2B) and Effective 4B (E4B). These are where Gemma 4 gets genuinely interesting from a deployment perspective. The E2B model has 5.1 billion total parameters but an effective inference footprint of just 2.3 billion. The E4B runs at 4.5 billion effective parameters from 8 billion total. Both support 128K token context windows - enough to process entire codebases or book-length documents.
Google's Pixel team collaborated with Qualcomm and MediaTek to optimize these models for smartphone chipsets. The E2B runs on a Raspberry Pi 5 with a prefill throughput of 133 tokens per second and decode throughput of 7.6 tokens per second, according to Google's LiteRT-LM benchmarks. These are numbers that make genuine on-device AI assistants feasible - not the stripped-down, can-barely-summarize-a-paragraph experience that current on-device models deliver, but actual multi-step reasoning and tool use running locally.
Both edge models also support native audio input - speech recognition and understanding without sending your voice to a server. Combined with vision capabilities (variable-resolution image processing, video understanding, OCR), these tiny models are genuinely multimodal in a way that matters for real applications.
Key technical detail: All Gemma 4 models use a novel Per-Layer Embeddings (PLE) architecture, first introduced in Gemma-3n, that gives each transformer layer its own conditioning signal. Traditional transformers force all information into a single initial embedding. PLE adds a parallel, lower-dimensional pathway that feeds layer-specific context throughout the network. The result: better quality per parameter, especially for multimodal inputs.
The License That Actually Matters

The shift from custom licensing to Apache 2.0 removes legal uncertainty that kept enterprises from building on Gemma. Photo: Unsplash
Strip away the benchmarks, the parameter counts, and the architecture innovations. The most consequential thing Google did with Gemma 4 is change a text file.
The previous Gemma license was a legal minefield that only corporate lawyers could love. It included a prohibited-use policy that Google could modify at any time. Developers who built products on Gemma 3 were, in effect, building on shifting ground - Google could redefine what counted as "prohibited use" after you had already shipped. The license also required developers to enforce Google's terms across all downstream projects using Gemma-derived models or data.
Worse, the synthetic data clause created genuine anxiety among AI researchers. If you generated training data using Gemma and then used that data to train a different model, the license could be read as extending Google's terms to that second model. For researchers at universities and companies working on model development, this was a dealbreaker. It meant touching Gemma could potentially contaminate your entire research pipeline.

Side-by-side: the restrictive Gemma 3 license versus the permissive Apache 2.0. BLACKWIRE PRISM
Apache 2.0 eliminates all of this. It is one of the most widely used and well-understood open-source licenses in software. It grants perpetual, worldwide, royalty-free rights to use, reproduce, modify, and distribute the software. Google cannot revoke it. Google cannot add new restrictions later. The license is the license, permanently.
This matters practically because it removes the legal risk calculus that enterprise decision-makers run before adopting any technology. A startup building a product on Gemma 4 does not need to worry about Google's next terms-of-service update. A defense contractor evaluating on-premises AI does not need to clear Google's prohibited-use list. A university researcher generating synthetic data can use it freely without license contamination concerns.
Google explicitly framed this as responding to developer feedback. "You gave us feedback, and we listened," the company's announcement states. That phrasing undersells what happened. The open-model ecosystem punished Google for its licensing choices. DeepSeek's MIT-licensed models captured developer mindshare specifically because they came with no strings attached. Alibaba's Qwen family, also Apache 2.0, ate into Gemma's potential market. Google did not listen to feedback out of goodwill - it responded to competitive pressure from Chinese AI labs that were shipping better terms alongside competitive performance.
The broader signal is that the market has spoken on AI licensing. Meta's Llama license, which includes its own set of restrictions (notably a 700 million monthly active user threshold for commercial use), now looks increasingly anachronistic. The trend line is clear: permissive licensing wins developer adoption, and developer adoption wins the ecosystem game. Expect Meta to face growing pressure to match Apache 2.0 for future Llama releases.
Architecture Deep Dive: Why Gemma 4 Punches Above Its Weight

Gemma 4's architecture innovations let smaller models compete with systems 20x their size. Photo: Unsplash
Performance-per-parameter is the metric that matters for open models. Anyone can build a massive model that performs well - the challenge is building a small model that performs well. Gemma 4's architecture includes several innovations that explain how a 31B model competes with systems running hundreds of billions of parameters.
Per-Layer Embeddings (PLE): Traditional transformers convert input tokens into a single embedding vector at the start, and the entire network builds on that initial representation. PLE adds a second, smaller embedding table that generates a unique conditioning signal for every layer. Think of it as giving each layer in the network its own private communication channel to the input, rather than forcing everything through a single bottleneck at the entrance. The computational cost is minimal - the PLE dimension is much smaller than the main hidden size - but the quality improvement is meaningful, especially for multimodal inputs where images and audio need different treatment at different depths of the network.
Shared KV Cache: Key-value caching is what makes transformer inference practical - it stores intermediate computations so the model does not have to recompute everything for each new token. Gemma 4 takes this further by having the last several layers share their key-value states with earlier layers of the same attention type. The result is substantially reduced memory usage during long-context generation without meaningful quality loss. For on-device deployment, where RAM is the binding constraint, this is the difference between running and not running.
Dual attention architecture: Gemma 4 alternates between local sliding-window attention layers (512 or 1024 tokens depending on model size) and global full-context attention layers. The sliding windows handle local patterns efficiently while the global layers capture long-range dependencies. Each type uses a different RoPE (Rotary Position Embedding) configuration - standard RoPE for local layers, proportional RoPE for global layers - which enables the extended context windows (128K for edge models, 256K for large models) without the quality degradation that typically comes from stretching positional encodings.
Variable-resolution vision encoder: Rather than resizing all images to a fixed resolution (which destroys detail in some images and wastes compute on others), Gemma 4's vision encoder preserves original aspect ratios and offers configurable token budgets - 70, 140, 280, 560, or 1,120 visual tokens per image. Developers can trade off between speed and visual fidelity based on their use case. An OCR application processing receipts can use fewer tokens. A medical imaging application can use more. This flexibility is rare in open models, where vision is typically bolted on as an afterthought.
The Mixture of Experts architecture in the 26B model adds another layer of efficiency. During inference, a routing mechanism selects which 3.8 billion parameters (out of 26 billion total) activate for each input. Different inputs activate different experts. The model effectively maintains the knowledge capacity of a 26B model while only paying the computational cost of a 3.8B model on each forward pass. This is why the 26B MoE can compete on Arena.ai with models that activate 10x to 20x more parameters.
The Competitive Landscape: Where Gemma 4 Fits

The open-model arena is now a five-way fight between Google, DeepSeek, Alibaba, Z.ai, and Moonshot. Photo: Unsplash
A year ago, the open-model leaderboard was dominated by Meta's Llama and Mistral's offerings. That world no longer exists. The Arena.ai open-source text leaderboard as of April 2026 tells the story of a dramatic power shift toward Chinese AI labs - and Google's attempt to fight back.
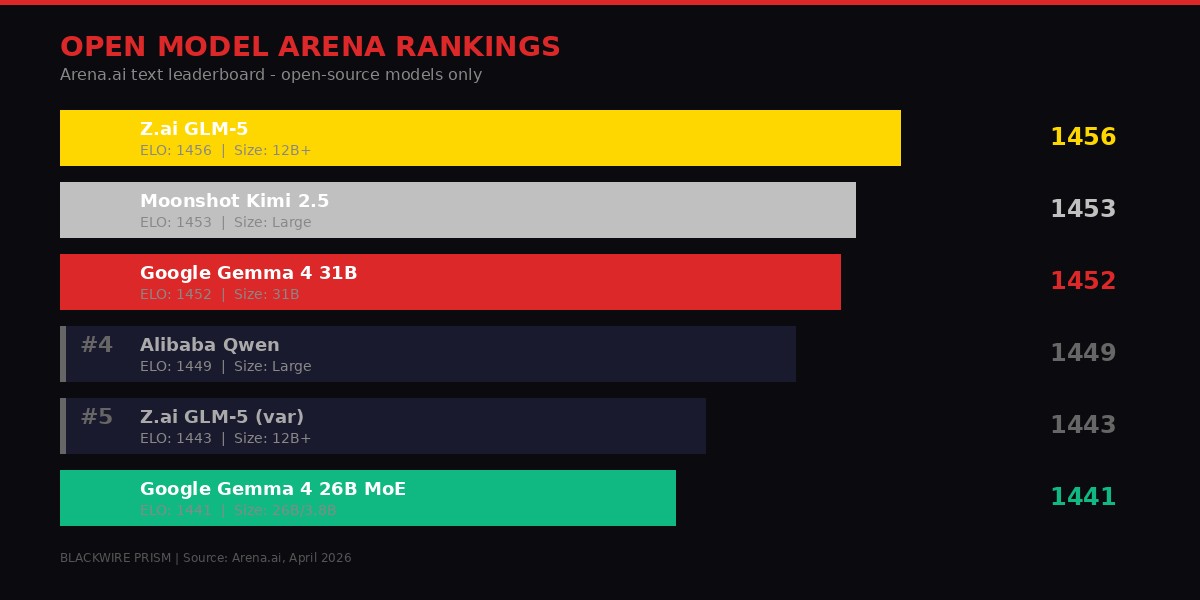
Open-source model rankings on Arena.ai, April 2026. Google's Gemma 4 claims the #3 and #6 spots. BLACKWIRE PRISM
The top 10 is now dominated by Z.ai, Moonshot, DeepSeek, and Alibaba. Google's Gemma 4 31B sits at #3 (ELO 1452) and the 26B MoE at #6 (ELO 1441). Meta's Llama does not appear in the top 10. Mistral's best open model sits at #24. The companies that defined "open AI" two years ago have been leapfrogged by organizations that ship faster, train more aggressively, and - crucially - offer more permissive licenses.
DeepSeek deserves particular attention. Its models appear at positions #10 through #20 on the leaderboard, all under MIT license, with notably cheap inference pricing ($0.21-$1.23 per million tokens input). DeepSeek proved that you could build frontier-competitive models with significantly less capital than Western labs assumed, and it did so while giving away the weights with essentially zero restrictions. That combination - competitive performance, low cost, total openness - set a new floor for what developers expect from open models.
Alibaba's Qwen family is equally prolific, with Apache 2.0-licensed models scattered throughout the top 50. Qwen's strategy has been quantity and variety - models optimized for different use cases, sizes, and deployment scenarios. Google's response with four carefully positioned Gemma 4 variants mirrors this approach but focuses on quality over quantity.
| Model | Organization | License | Arena Rank | ELO | Key Advantage |
|---|---|---|---|---|---|
| GLM-5 | Z.ai | MIT | #1 | 1456 | Raw performance |
| Kimi 2.5 | Moonshot | Modified MIT | #2 | 1453 | Reasoning depth |
| Gemma 4 31B | Apache 2.0 | #3 | 1452 | Quality per parameter | |
| Qwen (top) | Alibaba | Apache 2.0 | #4 | 1449 | Ecosystem breadth |
| Gemma 4 26B MoE | Apache 2.0 | #6 | 1441 | Speed (3.8B active) | |
| DeepSeek V3 | DeepSeek | MIT | #10 | 1425 | Cost efficiency |
The pattern emerging across all these models is convergence. The ELO gap between #1 and #10 is just 31 points - statistically marginal in many real-world tasks. Performance is becoming commoditized. The differentiators are shifting to licensing terms, deployment flexibility, ecosystem support, and fine-tuning efficiency. This is where Google's combination of Apache 2.0 licensing, four-size model family, and deep hardware partnerships (Qualcomm, MediaTek, NVIDIA) could prove decisive.
One notable absence from the leaderboard conversation: OpenAI. The company's open-weight model (ranked #54 with an ELO of 1354) is an afterthought compared to its proprietary offerings. OpenAI has made its strategic choice - proprietary models delivered via API - and the open-model community has moved on without it.
The Edge AI Revolution Gemma 4 Enables

Gemma 4's edge models bring genuine AI capabilities to smartphones without cloud dependency. Photo: Unsplash
The E2B and E4B models represent something more important than incremental improvements to on-device AI. They represent the first time a top-5 open model family has shipped variants specifically engineered for phones, IoT devices, and embedded systems with genuine agentic capabilities.
Google's AI Edge Gallery app, available on both iOS and Android, showcases what this means in practice. Developers can build "Agent Skills" - multi-step, autonomous workflows running entirely on-device. The demo applications include querying Wikipedia offline, generating interactive data visualizations from speech input, synthesizing music to match photo moods, and building complete applications through conversational interfaces. These are not chatbot tricks. They are function-calling, tool-using, multi-step reasoning systems running on hardware that fits in your pocket.
The LiteRT-LM framework handles the inference optimization. Google claims the E2B model can process 4,000 input tokens across two distinct agent skills in under three seconds on mobile hardware. On a Raspberry Pi 5 - a $80 computer the size of a credit card - the same model achieves 133 tokens per second prefill and 7.6 tokens per second decode. These numbers make genuine offline AI assistants feasible for the first time.
The implications extend beyond consumer devices. Industrial IoT deployments - factory floors, agricultural sensors, medical monitoring equipment - currently send data to cloud servers for AI processing. That creates latency, bandwidth costs, and privacy concerns. A model that runs locally with 128K token context and native vision capabilities can process sensor data, camera feeds, and log files without any network connection. For applications in healthcare (patient monitoring), agriculture (crop analysis), and manufacturing (quality inspection), this eliminates the cloud dependency that has been the primary barrier to AI adoption.
Google's collaboration with Qualcomm and MediaTek on chipset-level optimization is also significant. These are the companies that design the processors in most of the world's smartphones. When Google says "optimized for Qualcomm" and "optimized for MediaTek," it means the next generation of mid-range and flagship phones will ship with hardware specifically tuned to run Gemma 4 efficiently. The Pixel team's involvement confirms that Gemini Nano 4 - the next-generation on-device AI for Google's own phones - will be based directly on Gemma 4 E2B and E4B. Developers prototyping with Gemma 4 edge models today will have forward compatibility with Gemini Nano 4 when it launches, likely at Google I/O in May.
This is the smartphone AI play that Apple, Samsung, and every other device manufacturer will need to respond to. Apple's on-device models remain proprietary and inaccessible to third-party developers. Samsung uses a mix of Qualcomm's AI Engine and its own models. Neither offers the combination of open weights, Apache 2.0 licensing, and developer tooling that Google is shipping with Gemma 4. If on-device AI becomes a meaningful differentiator for smartphone buyers - and the trends suggest it will - Google just built a significant lead in the developer ecosystem that powers it.
The Agentic AI Play: Why This Architecture Matters Now

Gemma 4's native function-calling and structured output support positions it as the foundation for autonomous AI agents. Photo: Unsplash
Every major AI lab is now talking about "agentic" systems - AI that does not just generate text but takes actions, uses tools, and executes multi-step workflows autonomously. The rhetoric has outpaced reality. Most agent frameworks still require cloud-based models with sub-second latency and reliable function calling. Gemma 4 is designed to close that gap for local deployments.
All four Gemma 4 models include native support for function calling, structured JSON output, and system instructions. This is not a fine-tuned afterthought - it is baked into the base architecture. When a Gemma 4 model encounters a task that requires external tools (querying a database, calling an API, reading a file), it generates structured function calls in a predictable format. The structured JSON output means the model's responses can be reliably parsed by code without the brittle regex-based extraction that plagued earlier open models.
For the developer community building agent frameworks - LangChain, CrewAI, AutoGen, and their successors - this is the specification they have been waiting for. Previous open models supported function calling through fine-tuning and prompt engineering, producing inconsistent results. A model with native function-calling support means agent frameworks can rely on predictable behavior, reducing the engineering overhead of building reliable autonomous systems.
The 256K context window on the larger models amplifies this capability. An agent processing a codebase can hold entire repositories in context. An agent managing a workflow can maintain conversation history across dozens of tool interactions without losing track of its objective. A year ago, 256K context was the exclusive territory of cloud APIs charging premium rates. Now it runs on a single GPU in your office.
The code generation capabilities deserve separate mention. Google claims Gemma 4 can serve as a "local-first AI code assistant" - the offline equivalent of what GitHub Copilot, Cursor, and Claude Code provide as cloud services. For developers working in air-gapped environments (defense, finance, healthcare), on proprietary codebases they cannot send to external servers, or simply in locations with unreliable internet, this is a meaningful capability. The larger Gemma 4 models can process code with 256K tokens of context, meaning they can understand the structure of substantial projects without the chunking and retrieval hacks that smaller-context models require.
The practical implication: we are approaching a world where a developer's laptop contains a fully capable AI coding assistant, a multimodal content analyzer, and an autonomous agent runtime - all running locally, all under a license that imposes zero restrictions on use. The cloud is not dead, but its monopoly on advanced AI capabilities is ending.
What Gemma 4 Does Not Solve

Open-weight does not mean solved - safety, alignment, and the resource divide remain open questions. Photo: Unsplash
For all its technical achievements, Gemma 4 does not address several critical challenges in the open-model ecosystem.
Safety and alignment remain largely honor-system. Google states that Gemma 4 undergoes the same "rigorous infrastructure security protocols" as its proprietary models, but once the weights are released, anyone can fine-tune away safety guardrails. The Apache 2.0 license explicitly does not include behavioral restrictions - that is part of its appeal and part of its risk. The question of whether open-weight models enable harmful applications (bioweapons research, non-consensual deepfakes, automated disinformation) does not go away because the license is permissive. It just becomes someone else's problem.
The compute divide persists. Running the 31B model on a single H100 is technically feasible but economically exclusive. The people who benefit most from Gemma 4's capabilities are those who already have access to high-end hardware - well-funded startups, enterprise R&D labs, and researchers at wealthy institutions. The edge models help here, but the performance gap between E2B (2.3B effective parameters) and 31B Dense is enormous. The best open models are still the most expensive to run.
Training data transparency is limited. Google has not disclosed the full training dataset for Gemma 4. We know it was trained on over 140 languages and builds on "the same world-class research and technology as Gemini 3," but the specifics - what web data, what books, what code repositories, what synthetic data pipelines - remain opaque. For researchers trying to understand model behavior, reproduce results, or identify biases, this is a significant gap. Open weights without open data is an incomplete form of openness.
The fine-tuning resource gap is growing. While Gemma 4's architecture is optimized for fine-tuning, the competitive landscape increasingly favors organizations with massive compute budgets for post-training optimization. A startup can download Gemma 4 and fine-tune it on consumer hardware, but it will not match the fine-tuning results of a well-resourced lab running thousands of GPU-hours of RLHF and DPO. The model weights are open. The competitive advantage in making those weights maximally useful is not.
Evaluation remains noisy. Arena.ai rankings are based on human preference comparisons - real users chatting with anonymous models and picking which response they prefer. This methodology has known biases: it rewards verbosity, it favors English-language performance, and the user population skews toward tech-savvy early adopters. A model ranked #3 on Arena might rank #30 on a medical question-answering benchmark or a multilingual legal reasoning test. The single-number ELO ranking obscures more than it reveals about where these models actually excel and where they fail.
The Road Ahead: What Comes Next

Gemma 4 is not the destination - it is the starting gun for a new phase of open AI development. Photo: Unsplash
Google has confirmed that Gemini Nano 4 - the next-generation on-device AI for Pixel phones - will be based on Gemma 4 E2B and E4B. The AI Core Developer Preview is already available for Android developers to begin prototyping. We will likely hear specifics at Google I/O in May, but the trajectory is clear: the same AI capabilities currently locked behind cloud APIs will ship natively in the next generation of smartphones.
The Hugging Face ecosystem has already moved. Day-one support exists across Transformers, TRL (for fine-tuning), llama.cpp (for CPU inference), MLX (for Apple Silicon), Ollama (for one-click local deployment), NVIDIA NIM, and vLLM (for serving). The speed of ecosystem adoption reflects both the demand for a competitive open model with proper licensing and the infrastructure that the Gemma community - 400 million downloads across previous versions - has already built.
The competitive response will be swift. DeepSeek's next major release is expected in the coming months. Alibaba continues to iterate rapidly on Qwen. Meta's Llama 4 is in development. The open-model ecosystem is in an innovation sprint where each release raises the bar and compresses the timeline for the next. Performance parity at the top of the leaderboard means the competition is shifting to ecosystem support, deployment tooling, and - as Google just demonstrated - licensing terms.
For enterprises evaluating AI strategy, Gemma 4 creates a credible alternative to cloud API dependency. A company can now run frontier-competitive AI on its own hardware, under a license it fully controls, with no usage-based pricing and no data leaving its network. The cost calculation between "pay OpenAI/Anthropic/Google per token" and "buy hardware and run Gemma 4" just tipped further toward self-hosting for any organization with sufficient scale.
For the broader AI industry, Gemma 4 under Apache 2.0 accelerates a trend that has been building for a year: the commoditization of foundation models. When the #3 open model in the world runs on a single GPU and costs nothing to license, the value proposition of proprietary model APIs narrows to the thinnest use cases - those requiring the absolute frontier of capability, the longest context windows, or the deepest integration with cloud services. For everything else, open models are now good enough. And "good enough" with total control beats "slightly better" with vendor lock-in every time.
Google built Gemma 4 to win developers. The Apache 2.0 license is how it plans to keep them. Whether the strategy works depends less on benchmarks and more on whether Google can sustain the pace of iteration that Chinese labs have set. The open-model race is not a marathon. It is a sprint with no finish line.
Get BLACKWIRE reports first.
Breaking news, investigations, and analysis - straight to your phone.
Join @blackwirenews on Telegram