The $7 Trillion AI Waste Problem: Gimlet Labs Raises $80M to Fix Broken Inference
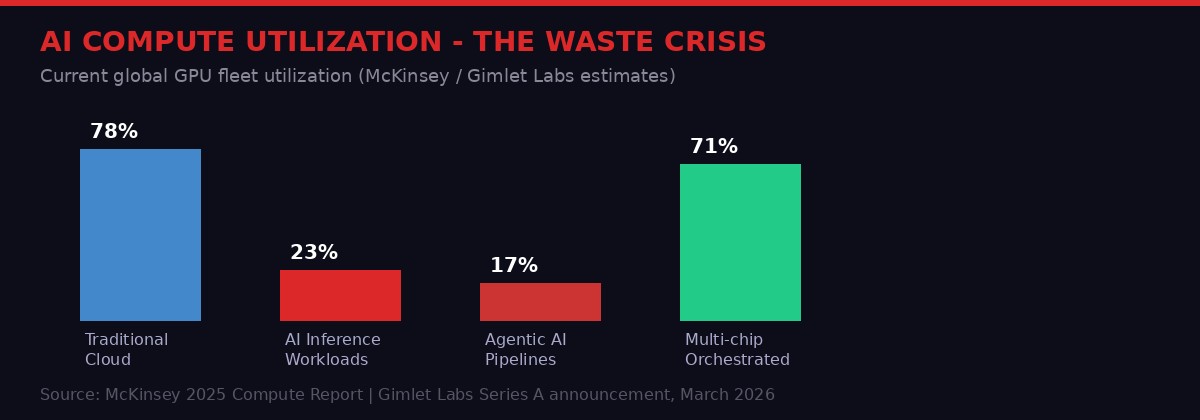
While the industry obsesses over which model is smartest, the hardware underneath is running at 15-30% utilization. A Stanford founder just raised $80 million to fix the actual problem: the software layer that wastes billions in deployed compute every single day.

The AI industry has a dirty secret it rarely discusses publicly. While billions of dollars flow into building the next frontier model and trillion-dollar valuations rest on the promise of artificial general intelligence, the physical infrastructure powering all of it is catastrophically underutilized. Not by a small margin. By a factor that would be embarrassing in any other industry.
According to McKinsey Global Institute research cited by Gimlet Labs founder Zain Asgar, global AI inference workloads use somewhere between 15 and 30 percent of deployed hardware capacity at any given moment. The rest sits idle, drawing power, consuming cooling, depreciating in value - while their owners pay for capacity they cannot actually use. McKinsey projects total data center spending will hit nearly $7 trillion by 2030. If utilization stays where it is, we're burning roughly $5 trillion to deliver $1.5 trillion worth of actual compute work.
That gap is the opportunity Gimlet Labs is racing to close. On March 23, 2026, the Stanford-linked startup announced an $80 million Series A led by Menlo Ventures, bringing its total raise to $92 million. The company's pitch is deceptively simple: build the software layer that was always missing - the one that can route AI workloads intelligently across any combination of chips, regardless of manufacturer or architecture, in real time.
Why Every AI Inference Pipeline Is Broken by Design
To understand why Gimlet Labs exists, you need to understand how modern AI inference actually works - and why the current approach is architecturally wrong from the start.
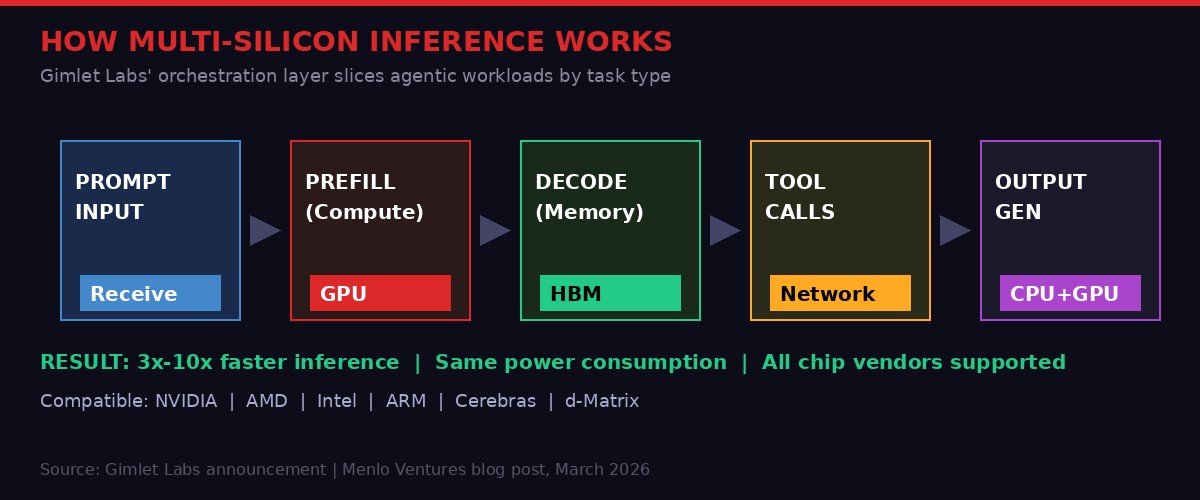
When you send a prompt to an AI model, the system needs to execute several distinct computational steps. The prefill phase - where the model reads and encodes your input - is compute-bound. It needs raw GPU muscle, the kind NVIDIA H100s and A100s excel at. The decode phase - where the model generates each new token in your response - is memory-bound. It needs fast memory bandwidth, which is what High Bandwidth Memory (HBM) systems are designed to deliver. The tool call phase - where an agentic AI executes external functions, searches databases, or calls APIs - is network-bound. That barely stresses a GPU at all.
The problem is that current AI deployment architectures treat all three phases as if they are identical. You rent a block of GPUs. You run all your inference on those GPUs. The GPUs do compute when they need to, wait when they don't, and the expensive memory-bandwidth capacity sits idle during the compute phases and vice versa. You're paying for a Swiss Army knife and mostly only using the bottle opener.
Menlo Ventures partner Tim Tully, who led the Series A investment, put it plainly in a post explaining the investment rationale: a single agentic AI task "requires different hardware - inference is compute-bound; decode is memory-bound; and tool calls are network-bound." No chip does all three things equally well. And because no chip does all three equally well, any system locked to a single chip type is structurally inefficient for agentic workloads by definition.
This was a manageable problem when AI meant running a single large model in batch mode. It becomes a crisis when AI means thousands of concurrent agents, each running multi-step pipelines, each requiring a different hardware profile for each step. That is the world we are building toward. The infrastructure was never designed for it.
What Gimlet Labs Actually Built
Gimlet Labs describes its product as the world's first "multi-silicon inference cloud." That label is worth unpacking because it distinguishes the startup from both existing inference optimization tools and from AI hardware vendors trying to solve the same problem through proprietary lock-in.
The core technology is orchestration software. Rather than replacing any hardware, Gimlet's system sits above the chip layer and dynamically routes workloads to the most appropriate available hardware in real time. In practice, this means an agentic pipeline running on Gimlet's system might route its prefill stage to a cluster of NVIDIA H100s, its decode stage to a high-bandwidth memory system, and its tool calls to standard CPU infrastructure - all within a single inference request, without the developer doing anything special to make this happen.
"We basically run across whatever different hardware that's available. Our goal was basically to try to figure out how you can get AI workloads to be 10x more efficient than ever, today." - Zain Asgar, CEO, Gimlet Labs (TechCrunch, March 2026)
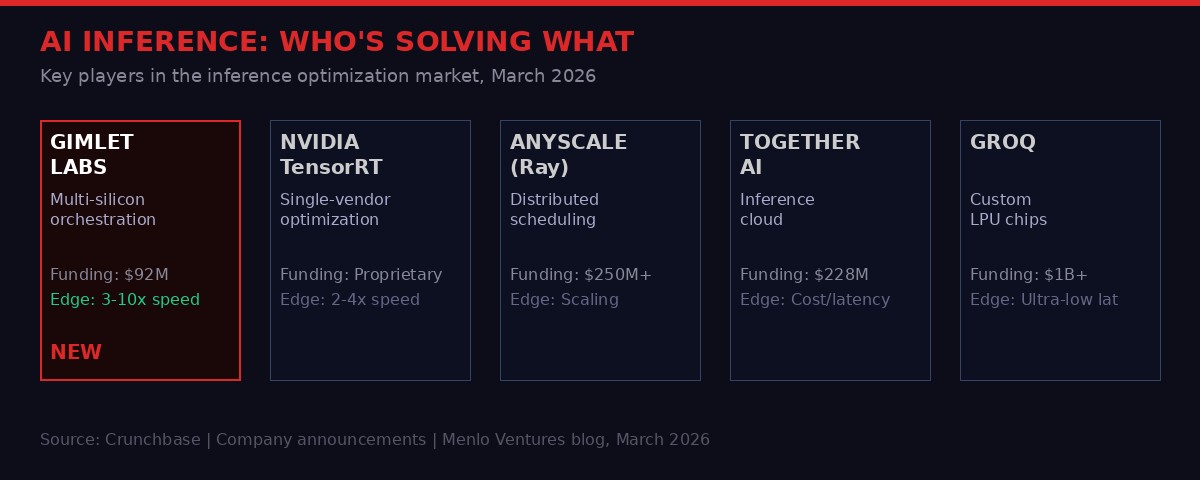
What makes this technically remarkable is that Gimlet claims to support not just different NVIDIA chips but the full spectrum of competing architectures simultaneously: NVIDIA, AMD, Intel, ARM, Cerebras, and d-Matrix. That breadth matters enormously. NVIDIA currently dominates AI training and inference workloads, but the entire industry - including the chip giants themselves - knows that a NVIDIA-only future is a strategic liability. Everyone from Google to Microsoft to Meta has launched their own custom silicon programs precisely to reduce dependence on one vendor. Gimlet's architecture is designed to benefit from, rather than be threatened by, that diversification.
The company claims this delivers 3x to 10x inference speed improvements for the same cost and power consumption. Even at the conservative end - three times faster - the economics are transformative. Data centers that were effectively operating at 20% capacity could, in theory, deliver the same output at 60% capacity, or triple their throughput without buying new hardware. Given that H100 clusters cost upward of $30,000 per unit and take months to procure, that headroom has direct dollar value.
Gimlet delivers its product either as software that customers deploy on their own infrastructure, or through a managed API via its own Gimlet Cloud. The company is not targeting individual developers or mid-market companies. Its customers are the largest AI labs and data center operators - the organizations whose hardware fleets are big enough for routing optimization to deliver meaningful returns at scale.
The Founders and the Funding Behind It
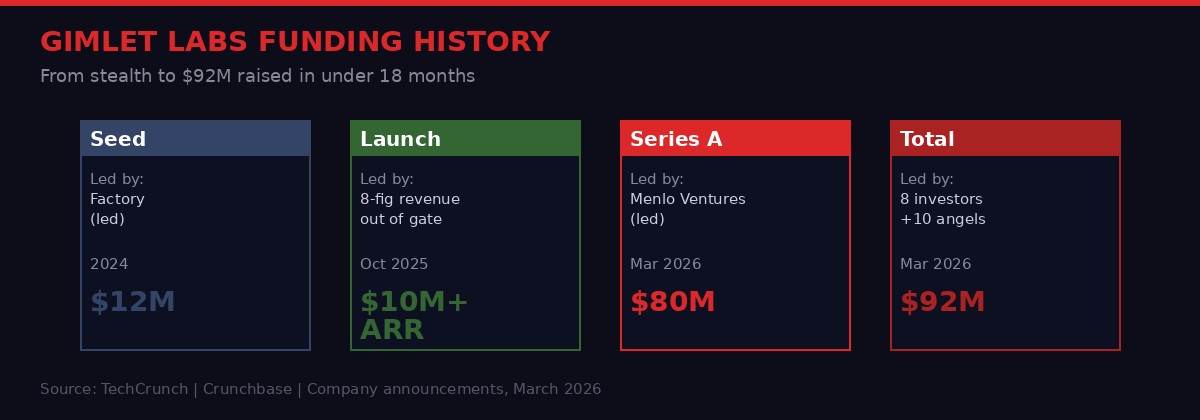
Zain Asgar is not a first-time founder betting on a good idea. He is an adjunct professor at Stanford and a repeat founder with a proven exit. His previous company, Pixie Labs, built an open source observability tool for Kubernetes - the kind of infrastructure-layer software that becomes invisible plumbing for the companies that adopt it. Pixie was acquired by New Relic in December 2020, just two months after launching with a $9 million Series A led by Benchmark. The team's ability to build deep infrastructure software quickly and attract enterprise adoption is exactly the pattern Gimlet is repeating.
The founding team - Asgar, Michelle Nguyen, Omid Azizi, and Natalie Serrino - all came through Pixie. They know how to build the boring, essential software layer that makes complex distributed systems work reliably. Inference orchestration is precisely that kind of problem: unglamorous, technically demanding, and worth enormous money to the companies for whom compute efficiency is a first-order cost center.
Gimlet publicly launched in October 2025 with a striking announcement: eight-figure revenues out of the gate. That means at least $10 million in annual revenue before the company had made any public noise about itself. In the four months since, the customer base has more than doubled. Asgar confirmed the customer list now includes a major AI model maker and an "extremely large" cloud computing company, though he declined to identify either.
The Series A was oversubscribed quickly. Asgar said that when VCs heard he was looking at offers, they received "a pretty big swarm of funding." The investor list reflects the establishment's belief in the thesis: Menlo Ventures led, with participation from Factory, Eclipse Ventures, Prosperity7, and Triatomic. The angel roster reads like a who's-who of infrastructure credibility - Sequoia's Bill Coughran, Stanford professors Nick McKeown and others, former VMware CEO Raghu Raghuram, and Intel CEO Lip-Bu Tan. That Intel's CEO is personally on the cap table is not incidental. Intel's AI chip ambitions have consistently fallen short of NVIDIA and AMD. A company whose value proposition is "all chips work better together" is a natural ally for every non-NVIDIA player in the market.
The Second-Order Problem: An Industry Built on Waste

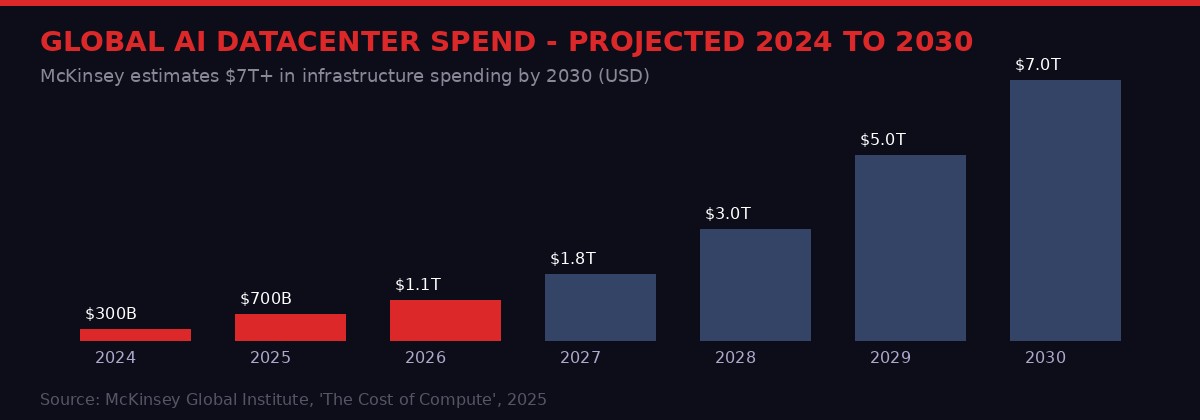
The Gimlet Labs story is a technology story, but it is also an economic story about how the AI industry got here and where it is going. The short version: the industry deployed capital faster than it could deploy software to use that capital efficiently.
The GPU scramble of 2023 and 2024 was driven by genuine scarcity. OpenAI, Google, Meta, and Microsoft were all racing to train the next generation of frontier models, and H100s simply could not be manufactured fast enough to meet demand. Hyperscalers paid enormous premiums, locked in multi-year supply agreements, and built out massive data centers with whatever they could get. The implicit assumption was that utilization would follow - that the software and the use cases would catch up with the hardware.
They have not caught up. Not fully. The explosion of AI usage has been real, but the architecture of how inference is served means that most of that hardware still runs hot only during bursts and idles the rest of the time. Training a model is a batch process - you can run GPUs at 90%+ utilization around the clock. Serving inference to real users is spiky, unpredictable, and structurally hard to optimize when you're locked to a homogeneous hardware fleet.
The rise of agentic AI has made this worse, not better. Traditional prompt-and-response workloads are relatively simple to profile and provision. Agentic workflows - where an AI agent might browse the web, execute code, query databases, and loop through reasoning steps before delivering a response - have wildly variable resource profiles within a single user session. A provisioning model designed for simple query-response fails badly when the workload profile changes every 200 milliseconds.
Asgar's framing of this is stark: "Another way to think about this: you're wasting hundreds of billions of dollars because you're just leaving idle resources." That is not hyperbole. At the scale of hyperscaler infrastructure, 15-30% utilization on a $200 billion hardware investment implies somewhere between $140 billion and $170 billion in annual waste from idle deployed assets. Even a modest improvement in effective utilization - say, from 22% to 45% - would functionally double the output of the existing deployed hardware base without buying a single additional chip.
Littlebird and the Other Edge of AI Infrastructure

The Gimlet story sits at the infrastructure layer, solving how AI runs. But there is a parallel wave of innovation happening at the interface layer - solving how AI understands and anticipates what you, specifically, need from it. That wave also moved forward on March 23, 2026, with a separate $11 million seed raise from a startup called Littlebird.
Littlebird's product is what happens when you take the Microsoft Recall concept - an AI that continuously reads your screen and builds a searchable memory of everything you've done on your computer - and rebuild it from scratch with different architectural choices. Where Microsoft's Recall captured screenshots (and ran into immediate and severe privacy backlash), Littlebird reads the screen as text and discards the visual data. The result is a dramatically smaller data footprint and a product that works through text extraction rather than screenshot storage.
The company was founded by Alap Shah, Naman Shah, and Alexander Green. The Shah brothers previously founded Sentieo, an institutional investor intelligence platform that was sold to AlphaSense. Alap Shah is also co-author of the viral "Citrini paper" that argued AI agents could structurally disrupt economic activity at scale - a paper that contributed to tech stock volatility in February 2026.
"We don't store any visual information. We only store text, which makes the data a lot lighter-weight. I think that was probably another reason that Recall and Rewind struggled, which is that taking a screenshot is a lot more data hungry. I also think it's more invasive." - Alexander Green, Co-founder, Littlebird (TechCrunch, March 2026)
The product captures context from applications you specify, ignores password fields and sensitive forms by default, integrates with Gmail and Calendar, and lets you query your own history in natural language. It also includes an ambient meeting transcription layer and a "Routines" feature that runs recurring analysis jobs on your captured context - things like daily briefings and weekly work summaries.
The obvious concern with this category is privacy. You are, fundamentally, building an AI that reads everything you do on a computer and stores it in a database. The attack surface is significant. Littlebird stores data in the cloud rather than locally, reasoning that powerful models cannot run on-device. Green argues that text is less invasive than screenshots, which is technically true but may not be a distinction most users make instinctively.
The $11 million seed round was raised in a market still grappling with what "always-on AI" actually means for personal privacy. Microsoft Recall was delayed, modified, and relaunched multiple times after initial backlash. Rewind was acquired by Meta after pivoting through several iterations. Littlebird is entering a category where the technical challenges are known and the market appetite is real, but where the margin for error on privacy incidents is essentially zero.
The Anthropic Fallout and What It Means for AI Companies
Both stories play out against a backdrop that is shifting the entire AI industry's risk calculus. The Pentagon's blacklisting of Anthropic - designating the AI lab as a "supply-chain risk" after it refused to allow its technology to be used for mass surveillance of Americans or in fully autonomous weapons decisions - has reached a critical legal inflection point.
On March 23, U.S. Senator Elizabeth Warren sent a letter to Defense Secretary Pete Hegseth, calling the designation "retaliation" and warning that the Pentagon appears to be trying to "strong-arm American companies into providing the Department with the tools to spy on American citizens." A court hearing in San Francisco on March 24 will determine whether District Judge Rita Lin grants Anthropic a preliminary injunction that would pause the designation while the case proceeds.
The broader implication for AI infrastructure companies like Gimlet Labs is significant. The Pentagon blacklist, as structured, requires any company doing government work to certify it does not use Anthropic's products or services. For a company whose technology sits at the infrastructure layer - below the model, handling raw inference routing - the question of what counts as "using" a vendor's product becomes genuinely complex. If Gimlet routes inference workloads that happen to land on Claude models, does that create exposure?
No one has answered that question yet. But as AI infrastructure becomes more abstracted and interdependent, the blast radius of any single vendor's legal or regulatory status grows. The Pentagon blacklist was designed for clear-cut supply chain relationships. It was not designed for a world where an inference orchestration layer might simultaneously route to Claude, GPT-5, Gemini, and Llama in a single agentic session.
The tech industry's response to the Anthropic situation has been striking in its breadth. Employees from OpenAI, Google, and Microsoft have filed amicus briefs in support of Anthropic's legal position. The rare sight of major competitors publicly defending each other against government pressure reflects a shared recognition that the precedent being set - the ability of a government agency to blacklist an AI company for refusing to cross self-defined ethical lines - affects everyone building in this space.
The Convergence: Why These Moves Matter Together
Take a step back from the individual announcements and a clearer picture emerges. Three distinct things are happening simultaneously in the AI infrastructure layer, and they are not unrelated.
First, the raw compute layer is becoming more diverse and harder to manage efficiently. The days of NVIDIA-homogeneous AI infrastructure are numbered, both by market forces and by deliberate decisions from hyperscalers to develop custom silicon. Any software layer that can't route across the full chip spectrum will be a legacy system within three years.
Second, agentic AI is creating a new infrastructure demand profile that existing systems were never designed for. The assumption that inference is a simple prompt-to-response operation is already obsolete. Modern AI workloads are multi-step, multi-tool, and radically heterogeneous in their hardware requirements within a single user session. The software infrastructure needs to catch up.
Third, the legal and regulatory environment is becoming a first-class infrastructure concern. The Anthropic situation is the first major case where an AI company's values - specifically, its refusal to let its technology be used for certain applications - have been weaponized against it through a supply chain mechanism. For any company building at the infrastructure layer, this changes the threat model. You are not just building software that needs to work technically. You are building software that needs to survive in a regulatory environment that is actively being shaped by actors with specific interests in how AI systems are controlled.
Gimlet Labs' $80 million bet is that multi-silicon orchestration is not a niche optimization problem but a foundational layer of how AI runs at scale. Given the numbers - 15-30% utilization against $7 trillion in projected spend - the opportunity math works even if the company only captures a fraction of the efficiency gains it promises. The question is whether it can build the partnerships, the reliability, and the trust required to become invisible infrastructure for the companies managing the world's most valuable compute resources.
That is exactly what good infrastructure software does. It disappears. It becomes the thing you never think about because it always works. Pixie became Kubernetes plumbing. Gimlet is trying to become AI compute plumbing. The challenge is getting there before NVIDIA's own orchestration tools, before AWS and Azure build it natively, and before the chip vendors figure out that the most valuable position in the stack might be the one connecting all of them together.
Key Events Timeline
WHAT TO WATCH
- Judge Lin's ruling on Anthropic's preliminary injunction - will set precedent for how government can treat AI vendors who impose ethics constraints
- Gimlet Labs' unnamed major model maker and cloud customer - likely one of the top 3 hyperscalers given the scale requirements
- NVIDIA's response: the company's own inference optimization tools (TensorRT, Triton) compete directly with what Gimlet is building, and NVIDIA has the distribution advantage
- Apple WWDC June 8 - "AI advancements" in iOS 27/macOS 27 will define Apple's on-device vs. cloud inference strategy for the next cycle
- Littlebird's privacy architecture under scrutiny: screen-reading AI that stores data in the cloud is a high-value target for security research and regulatory attention
Get BLACKWIRE reports first.
Breaking news, investigations, and analysis - straight to your phone.
Join @blackwirenews on Telegram