The Memory Wall Breaks: Google's TurboQuant Compresses AI Brains 6x - With Zero Accuracy Loss
Google Research just published a compression algorithm that cuts AI model memory consumption by a factor of six, runs 8x faster on Nvidia H100 GPUs, requires no retraining, and - in rigorous benchmark testing - loses zero measurable accuracy. This is not a tradeoff. This is the memory wall breaking.

Every time a large language model generates a word, it performs a calculation called attention. It needs to compare the current word against everything it has read so far - the entire context window - before deciding what to say next. That comparison requires storing a massive lookup table called the key-value cache, or KV cache. As context windows have grown from 2,000 tokens in 2020 to over one million tokens in Gemini 1.5, the KV cache has ballooned from a small overhead into the single biggest consumer of GPU memory during inference.
The result is an industry-wide bottleneck. Serving large models at scale is expensive primarily because of KV cache memory pressure. Longer contexts cost exponentially more. Running a model with a 1 million token context window on a single H100 GPU - which has 80 GB of VRAM - is simply impossible without aggressive compression. The GPU fills up before the model finishes reading the document.
On March 26, 2026, Google Research published a blog post and accompanying papers introducing TurboQuant, a new compression algorithm that addresses this bottleneck directly. The research will be formally presented at ICLR 2026 (International Conference on Learning Representations), one of the premier machine learning venues. The team behind it includes researchers from Google, Google DeepMind, KAIST, and NYU.
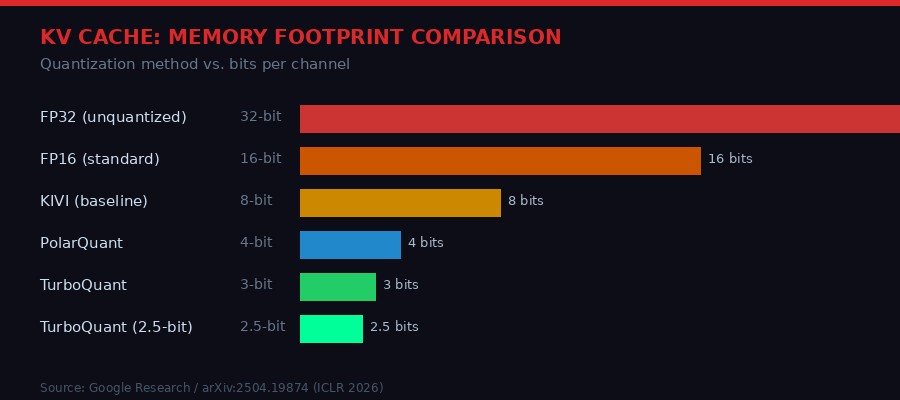
The headline numbers are striking. TurboQuant compresses the KV cache to just 3 bits per channel with zero accuracy loss across all tested benchmarks. That is a 6x reduction from the standard 16-bit floating point representation. Attention computation speeds up by up to 8x on H100 accelerators. No training or fine-tuning of the model is required. The runtime overhead of applying TurboQuant is described as "negligible."
Why This Matters: The KV Cache Bottleneck Explained
To understand why TurboQuant is significant, you need to understand what the KV cache actually is and why it consumes so much memory.
Large language models process text through a mechanism called transformer attention. When a model reads the sentence "the cat sat on the mat," it does not just process each word in isolation. It computes a relationship score between every word and every other word. To avoid recomputing these relationships from scratch for every new token it generates, the model stores intermediate results - the keys and values - in a cache. This is the KV cache.
For a typical GPT-4-class model with a 128,000 token context window, the KV cache can easily consume 20-40 GB of GPU memory during a single inference call. That is before you account for the model weights themselves. If you want to run multiple conversations concurrently on the same GPU - which is how AI serving infrastructure actually works - the KV cache becomes the limiting factor almost immediately.
The standard approach to dealing with this has been quantization: reducing the numerical precision of stored values from 32-bit floats to 16-bit, or even 8-bit integers. Each reduction halves memory, but each step also introduces errors. At 4 bits, many existing quantization methods start showing measurable accuracy degradation. Below 4 bits, degradation becomes a serious problem for most tasks.
"Traditional vector quantization usually introduces its own memory overhead as most methods require calculating and storing quantization constants for every small block of data. This overhead can add 1 or 2 extra bits per number, partially defeating the purpose of vector quantization." - Google Research TurboQuant blog post, March 2026
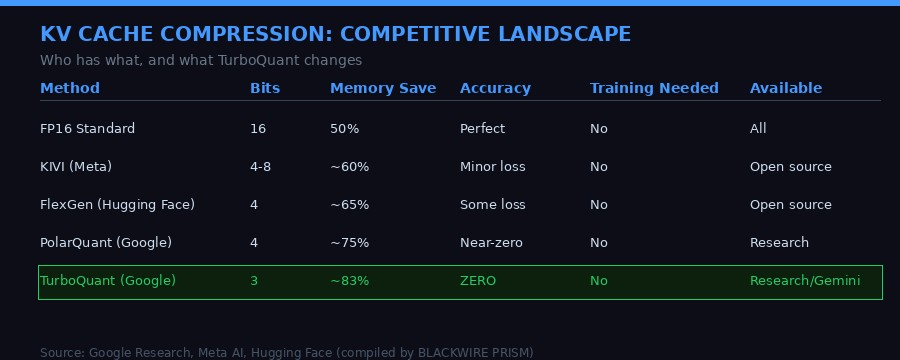
The previous state of the art for lossless KV cache compression was roughly 4 bits per channel - achieved by methods like KIVI from Meta and similar work from Hugging Face. Getting below 4 bits without accuracy loss has been an open problem. TurboQuant solves it, reaching 3 bits without any measurable degradation, and 2.5 bits with only marginal quality loss on the most demanding tasks.
For context, each 0.5-bit reduction across a large model's KV cache translates to meaningful real-world savings at scale. At Google's inference volumes - serving hundreds of millions of Gemini queries per day - the total GPU-hour savings from a 6x memory reduction are enormous. But the more immediate effect is capability: models that could not previously handle long contexts can now do so within existing hardware budgets.
The Technical Core: Two Algorithms Working Together
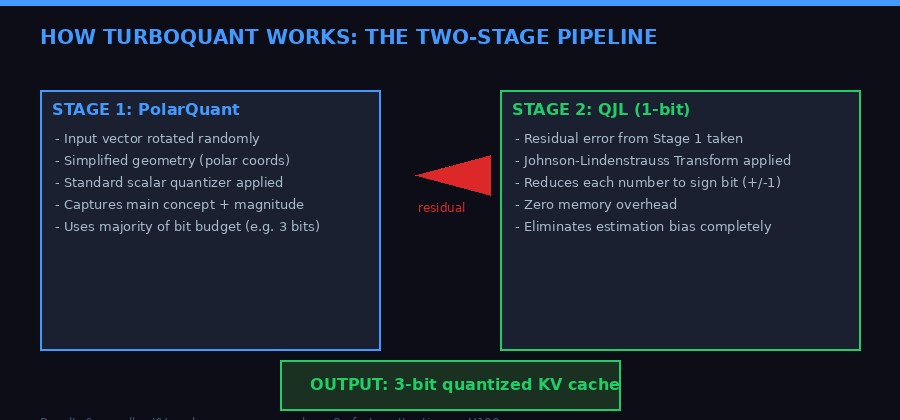
TurboQuant is not a single algorithm - it is a carefully engineered combination of two techniques: PolarQuant and Quantized Johnson-Lindenstrauss (QJL). Understanding how they work together explains why the results are so clean.
The fundamental challenge in quantizing vectors is that standard coordinate systems - the X, Y, Z axes we learned in school - do not play well with compression. When you have a 1,000-dimensional vector (which is typical for LLM attention heads), the data does not distribute uniformly across those dimensions. Some dimensions carry a lot of information, others carry almost none. Standard quantizers treat all dimensions equally, which wastes bits on low-information dimensions while starving the high-information ones.
PolarQuant solves this with a geometric trick. Instead of storing vectors in Cartesian coordinates (distance along each axis), it converts them to polar coordinates (a radius representing magnitude, plus angular components). The radius captures how "strong" the underlying concept is. The angles encode where the concept points in meaning-space. Because the angular distribution of vectors in high dimensions is highly concentrated and predictable, PolarQuant can apply a fixed quantizer grid without needing to compute or store normalization constants. That eliminates the 1-2 bit overhead that plagued previous methods.
But PolarQuant alone still leaves a small residual error in the attention score calculation. This is where QJL comes in. The Quantized Johnson-Lindenstrauss transform takes the tiny leftover error and compresses it to a single sign bit - either +1 or -1. This works because of a remarkable mathematical property of the Johnson-Lindenstrauss lemma: you can preserve the relative distances and dot products between high-dimensional vectors with surprisingly minimal information. One sign bit is enough to correct the estimation bias introduced by the first stage.
The result is a two-stage system. Stage 1 (PolarQuant) uses roughly 3 bits to capture the main signal. Stage 2 (QJL) uses exactly 1 bit to remove estimation bias. Total: approximately 3-4 bits per channel. Versus FP16's 16 bits. Versus FP32's 32 bits. The theoretical proof in the paper - which provides lower bounds on achievable distortion rates - shows that TurboQuant operates within a constant factor (approximately 2.7x) of information-theoretic optimality. You cannot do much better without violating fundamental limits of information theory.
What TurboQuant Actually Does (Plain English)
- Step 1: Randomly rotate the input vector. This spreads information more evenly across dimensions, making compression cleaner.
- Step 2 (PolarQuant): Convert to polar coordinates. No normalization overhead. Apply a fixed quantizer. Store in ~3 bits.
- Step 3 (QJL): Take the tiny error left over. Apply a mathematical transform. Reduce to 1 sign bit. This eliminates bias.
- Result: A 3-bit compressed key/value that computes attention scores as accurately as the 16-bit original, but six times smaller.
The elegance here is worth pausing on. Most engineering solutions to the memory problem involve a tradeoff: less memory for slightly worse output. TurboQuant is not a tradeoff solution. It is a mathematically principled argument that the standard approach was leaving bits on the table - and a proof that a smarter representation can recover those bits. The performance numbers back this up across every benchmark the Google team ran.
Benchmarks: Where the Claims Hold Up Under Pressure
Google tested TurboQuant against a rigorous battery of benchmarks designed specifically to stress-test long-context AI performance. The benchmarks included LongBench (diverse long-document tasks), Needle In A Haystack (finding specific information buried in massive texts), ZeroSCROLLS, RULER, and L-Eval.
The models tested were Gemma (Google's open-source model family) and Mistral (the French open-source model). These are reasonable proxies for the architecture patterns used in much larger models like Gemini.
The needle-in-a-haystack task is particularly revealing. It asks a model to find one specific piece of information hidden in up to 128,000 or more tokens of text - the equivalent of a full novel. For this task, KV cache accuracy is critical: if you compress the cache in a way that degrades attention quality, the model starts missing the needle. TurboQuant achieved perfect downstream results on needle tasks while reducing KV cache size by a minimum of 6x. No other method tested came close to this combination.
For vector search tasks - which are distinct from but related to KV cache compression - TurboQuant also outperformed Product Quantization (PQ) and RabbiQ, the current state-of-the-art methods, on recall metrics. And it does this with near-zero preprocessing time, compared to the expensive offline training that competing methods require. You do not need to build an index ahead of time with TurboQuant. You apply it on the fly.
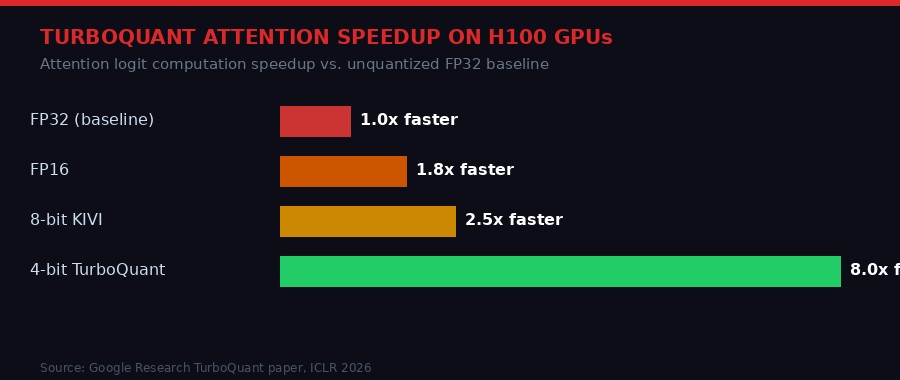
The speed improvement on H100 GPUs deserves its own examination. The 8x speedup in attention computation at 4-bit precision comes from a combination of factors. First, smaller data means more data fits in the GPU's L2 cache and registers. Second, the attention computation itself - which involves large matrix multiplications - benefits from the reduced memory bandwidth requirements. H100s are extraordinarily fast at compute, but they are often bottlenecked by the speed at which data can be moved from DRAM into the compute cores. TurboQuant makes that data 6x smaller, which directly translates to faster data movement and thus faster overall computation.
At 8x faster attention with 6x less memory, TurboQuant effectively lets you serve six conversations for the cost of one - or handle context windows six times longer at the same cost.
The AI Memory Crisis: Why This Research Arrived When It Did

TurboQuant did not emerge in a vacuum. It is the latest escalation in an arms race between AI capability and hardware constraints that has been building since 2022.
When OpenAI launched GPT-3 in 2020, its 2,048-token context window was generous by the standards of the day. The KV cache consumed maybe 1-2 GB of GPU memory. Not a crisis. When GPT-4 launched in 2023 with a 32,000-token context option, the math changed. A full 32K context with GPT-4's 96-layer architecture consumed the majority of a single A100 GPU's 80 GB of VRAM just in KV cache.
Anthropic's Claude models began offering 100,000-token contexts in 2023. Google's Gemini 1.5 Pro offered 1,000,000 tokens in 2024. Each step required either massively expensive hardware clusters to serve a single conversation, or aggressive engineering to compress the KV cache without breaking the model's ability to reason over long distances in the text.
The research community responded with a wave of compression techniques. FlashAttention from Stanford dramatically reduced the computational cost of attention. Grouped Query Attention (GQA) reduced the number of KV heads that needed to be cached. Speculative decoding allowed faster generation. But KV cache memory pressure remained the binding constraint for long-context deployment at commercial scale.
By 2025, the problem had become acute for the new wave of open-source models. DeepSeek R2, Llama 4, and their competitors all offered long contexts, but consumer and enterprise GPU deployments could not serve them efficiently. Researchers at Meta, Hugging Face, Stanford, and MIT published numerous quantization approaches - KIVI, MagicPIG, PyramidKV, AdaKV - each chipping away at the problem. Each reached different points on the accuracy-compression tradeoff curve.
TurboQuant arrives as the theoretical bookend to this work: a method with provable near-optimality guarantees, no training requirement, and clean zero-loss performance at 3 bits. It sets a new benchmark that other methods will now be measured against.
Second-Order Effects: What Changes When Memory Becomes Cheap

The obvious implication of TurboQuant is cost reduction. If Google deploys this in Gemini's serving infrastructure, it immediately cuts memory requirements by up to 6x. That translates to either 6x fewer GPU servers needed to serve the same number of users, or 6x more users served on the same infrastructure, or some combination of the two. At Google's scale, where AI inference costs run into the hundreds of millions of dollars per quarter, this is a material financial impact.
But the more interesting second-order effects are about capability, not cost.
Context window democratization. Today, 1-million-token context is a capability available only to the largest cloud providers with the most expensive GPU clusters. If TurboQuant-class compression becomes standard, a 1-million-token context becomes feasible on a single H100 node. That makes extremely long-context AI accessible to smaller companies, research institutions, and even well-resourced individuals running local AI setups. The context window ceiling moves up by a factor of six.
Real-time document analysis. One of the most commercially valuable applications of long-context AI is analyzing entire document sets - legal contracts, financial filings, medical records - in a single inference call rather than chunking them. This has been limited by KV cache memory. A 6x compression means a model that previously needed to be fed a 500-page document in ten chunks can now read the whole thing in one pass. The quality improvement from single-pass analysis over chunked analysis is significant and well-documented.
On-device and edge AI. Mobile phones and edge devices have a few gigabytes of available RAM, not hundreds. The gap between what a flagship phone can run and what a cloud server can run has been measured partly in KV cache requirements. TurboQuant does not close this gap entirely, but it narrows it. A model that previously required 12 GB of RAM for a 32K context might now operate within 2-3 GB. That is within reach of high-end smartphone memory.
Multi-user serving efficiency. AI inference infrastructure is almost always memory-bound before it is compute-bound. That means the bottleneck on how many simultaneous users a GPU can serve is usually KV cache memory, not GPU computation. TurboQuant directly addresses the binding constraint, potentially multiplying the number of concurrent users a fixed hardware pool can serve. This is the infrastructure equivalent of suddenly getting six-lane highways instead of two-lane roads.
Search at Google scale. The research blog specifically mentions vector search as a target application. Google runs one of the largest semantic search systems in the world. TurboQuant's near-zero preprocessing time and strong recall metrics mean it can be applied to Google's vector search index without expensive offline retraining. Faster, cheaper, more accurate semantic search has implications for everything from Google Search results to Google Maps to YouTube recommendations.
The Competitive Landscape: What Google Just Did to Everyone Else
Google publishing TurboQuant as open research - rather than keeping it proprietary - is a strategic choice worth analyzing. The paper will be presented at ICLR 2026, which means the methods, proofs, and code will eventually be fully public. Google is not trying to lock this up.
The competitive calculation is interesting. Google benefits from TurboQuant regardless of whether its competitors use it. If OpenAI, Anthropic, Meta, and Mistral all adopt TurboQuant-class compression, the entire industry's inference costs drop. That sounds like it hurts Google, but consider what happens next: the savings get reinvested in larger models, longer contexts, and more inference calls. That increases demand for Nvidia GPUs, Google Cloud TPUs, and the entire AI infrastructure stack. Google is deeply embedded in that stack.
Furthermore, Google's Gemini models benefit disproportionately from long-context efficiency improvements because Gemini was specifically designed around long-context reasoning. A technology that makes 1-million-token context 6x cheaper plays directly to Gemini's architectural strengths in a way that benefits Google more than, say, OpenAI's GPT series, which has historically focused on shorter contexts.
The paper's impact on the research community will also be significant. TurboQuant includes formal information-theoretic lower bound proofs - meaning it has demonstrated not just that its method works, but approximately how close it is to the best any method could theoretically achieve. This is the kind of theoretical clarity that moves an entire field. Rather than continuing the current proliferation of competing quantization heuristics, researchers now have a benchmark with proven near-optimality. Methods that do not meet or beat TurboQuant's bound will be harder to justify publishing.
For Anthropic and OpenAI, both of which operate their own inference infrastructure, TurboQuant presents a choice: implement it, wait for a competitor's equivalent, or develop something better. Given that TurboQuant operates near the theoretical optimum, "something better" is a high bar. The most likely path for both companies is adoption - either directly or through their GPU vendors' software stacks.
Nvidia's CUDA ecosystem and cuDNN library will almost certainly incorporate TurboQuant-compatible operations. Hugging Face's Transformers library and vLLM, the dominant open-source inference server, will likely add TurboQuant support within months of the ICLR presentation. At that point, the technique effectively becomes table stakes for any serious AI deployment.
What TurboQuant Doesn't Fix (And What Comes Next)

TurboQuant is a significant advance in KV cache compression. It is not a solution to all of AI's resource consumption problems. A clear-eyed assessment requires distinguishing what it fixes from what it does not.
The KV cache is one of three major memory consumers in AI inference. The other two are the model weights themselves (the neural network parameters) and the activation tensors during computation. TurboQuant specifically addresses the KV cache. Model weight quantization is a separate field - methods like GPTQ, AWQ, and GGUF quantize the model parameters rather than the inference-time cache. These are complementary techniques, not competing ones. Deploying both simultaneously stacks the benefits.
There is also the question of what happens at the 2.5-bit level. TurboQuant achieves absolute quality neutrality at 3.5 bits and "marginal quality degradation" at 2.5 bits. For tasks where marginal degradation is acceptable - casual conversation, draft generation, some classification tasks - 2.5 bits opens up another 20-30% memory savings beyond the 3-bit figure. But for high-stakes tasks like legal document analysis or medical reasoning, 3.5 bits is probably the floor.
The computational overhead of applying TurboQuant is described as negligible, but "negligible" has a specific meaning in the context of real-time inference. If TurboQuant adds even 2-3 milliseconds of overhead per token generated, that matters for latency-sensitive applications. The paper reports that 4-bit TurboQuant achieves up to 8x speedup over unquantized keys in attention computation. The "up to" qualifier is important - real-world gains depend on batch size, hardware configuration, and implementation quality.
None of these caveats significantly diminish the breakthrough. They simply clarify its scope. TurboQuant solves a specific, important, well-defined problem: KV cache memory overhead during transformer attention. It does this provably near-optimally, with no training requirement, and with verified benchmark results. That is rare in applied ML research, where most papers report gains under very specific conditions that do not always generalize.
Looking forward, the Google Research team identifies two major future directions. First, integrating TurboQuant directly into Gemini's serving infrastructure at scale. This is not just a proof of concept - the research explicitly mentions Gemini as a primary target application. Second, applying the same mathematical framework to vector search infrastructure across Google's products. Given that Google operates one of the largest search indexes in the world, optimizing vector quantization in that system has potentially enormous downstream effects on search quality and cost.
A Field That Rewarded Hardware; Now Rewards Mathematics

There is a broader story embedded in TurboQuant's release. From 2020 to 2023, progress in AI capability was driven primarily by scale: more parameters, more data, more compute. The companies that won were the ones with the biggest hardware budgets and the fastest access to Nvidia GPUs. Efficiency was a secondary concern - something you worried about after you had established capability.
That era is not over, but it is being joined by a new era of algorithmic efficiency. DeepSeek's R1 model demonstrated that you could match GPT-4-class performance at dramatically lower training cost by using smarter training algorithms. Speculative decoding cut inference latency without changing the underlying model. Flash Attention reduced memory IO bottlenecks. Now TurboQuant attacks KV cache overhead with a mathematically principled solution.
Each of these advances shares a common structure: they do not add capability by throwing more hardware at the problem. They recover efficiency by understanding the problem more precisely. DeepSeek asked "can we train with less compute if we structure the training differently?" TurboQuant asks "can we store attention state with fewer bits if we choose the right coordinate system?" Both answered yes.
The implication for the competitive landscape is significant. When AI progress was purely a function of hardware scale, the barriers to entry were enormous. Nvidia GPU allocation, power infrastructure, cooling systems - these were the competitive moats. Algorithmic advances commoditize capability. If TurboQuant becomes standard, then one of the meaningful cost advantages of operating at Google or OpenAI scale narrows. Smaller models running on less expensive hardware, equipped with TurboQuant-class compression, close some of the gap with the giants.
This is not a coincidence. It is consistent with what has happened in every previous generation of computing. Hardware improvements come in waves. Between waves, software catches up - and often permanently resets the cost structure of the industry. The transformer attention mechanism was an algorithmic breakthrough that defined AI's current era. TurboQuant is not at that scale, but it is in the same tradition: a mathematical insight that changes what is possible and how much it costs.
The paper is publicly available on arXiv (arXiv:2504.19874). It is worth reading - not just for the algorithms, but for the proofs, which provide a rigorous framework for thinking about the information-theoretic limits of attention state compression. For anyone building AI systems at scale, this is a paper that belongs on the desk, not in the unread folder.
Key Takeaways
- TurboQuant compresses transformer KV cache by 6x (16-bit to ~3 bits) with zero accuracy loss on standard benchmarks
- 8x attention speedup on H100 GPUs at 4-bit precision - directly reducing inference latency and GPU costs
- No model retraining required - drop-in applicable to existing deployed models
- Proven near-theoretically-optimal: within 2.7x of information-theoretic lower bounds
- Primary target: Gemini long-context serving and Google's vector search infrastructure
- Presented at ICLR 2026 - will become publicly available for adoption across the industry
- Second-order effect: democratizes 1M+ token contexts to significantly smaller hardware budgets
- Part of a broader industry shift from scale-driven to algorithm-driven AI efficiency gains
Get BLACKWIRE reports first.
Breaking news, investigations, and analysis - straight to your phone.
Join @blackwirenews on Telegram